![]() ISSN 0798 1015
ISSN 0798 1015

![]() ISSN 0798 1015
ISSN 0798 1015
Vol. 39 (Número 53) Año 2018. Pág. 11
Darío A. RODRÍGUEZ A. 1; Alejandra ROJAS A. 2; Ana M. RINCÓN V. 3
Recibido: 31/05/2018 • Aprobado: 15/07/2018 • Publicado: 11/11/2018
RESUMEN: La comunicación es un proceso fundamental, el mantener una intencionalidad, lograr un efecto en el interlocutor haciendo uso adecuado del lenguaje y de las herramientas comunicativas se denomina bienestar comunicativo. No obstante, la población sorda presenta limitaciones que lo impactan, secundarias al desconocimiento de la lengua de señas por parte de los oyentes, en este documento se contextualiza la propuesta de desarrollo de una herramienta de mediación comunicativa que permite a sordos y oyentes comunicarse de manera asertiva. |
ABSTRACT: Communication is a fundamental process; communicative wellness is related to maintain an intentionality and achieve an effect over the interlocutor using adequately language and communicative tools. However, the deaf population has limitations that affect his life, these are associated to the low level of knowledge of the sign language by the listeners, as an answer to this situation, this document is related to the development of a communicative mediation tool that allows deaf people and listeners to communicate. |

En el contexto Colombiano se han implementado esfuerzos importantes con el objetivo de favorecer la accesibilidad y la inclusión de las personas con discapacidad; pese a estos esfuerzos la población sorda aún enfrenta dificultades para desenvolverse con naturalidad, pues dada su limitación y el desconocimiento de la lengua de señas como código comunicativo han estado expuestos ante situaciones complicadas para llevar a cabo actividades del día a día, por ejemplo, cuando deben acudir a una cita médica o quieren estudiar, lo que claramente limita no solo en el acceso a la salud y a la educación sino también el bienestar comunicativo de dicho grupo poblacional.
Para (Cuervo, 1998), el bienestar comunicativo se distingue cuando el sujeto logra desarrollar de manera adecuada la capacidad para usar el lenguaje y la comunicación. Vale la pena precisar que estos elementos se dilucidan durante una situación comunicativa y de interacción, por lo que es necesario que tanto emisor como receptor manejen el mismo código comunicativo.
A partir de este panorama y dada la evidente la necesidad de generar herramientas encaminadas a disminuir la brecha comunicativa existente entre personas sordas y oyentes, la Universidad Manuela Beltrán, ha propuesto la generación de un sistema orientado a favorecer los procesos de comunicación e interacción en la población mencionada, permeando significativamente en el bienestar comunicativo; sin embargo, dada la amplitud de esta iniciativa y comprendiendo que es altamente ambiciosa, vale la pena precisar que esta se encuentra en curso. Por lo que en este documento se abordará únicamente la parte de este reto que involucra el problema de comunicación en dirección oyente hacia el sordo.
Por otra parte, debido a la riqueza del idioma (español) y las múltiples variaciones de los procesos de comunicación en el día a día, fue necesario acotar el contexto de funcionamiento y validación de la herramienta; para esto, se identificó un estudio realizado por el INSOR (Instituto Nacional para Sordos, Colombia) en 2011 (Martin Mateos, F.J. y Ruiz Reina, J.L., 2013), en el cual se evidencia que un gran porcentaje de la población sorda colombiana, percibe rechazo en la atención en servicios de salud; adicionalmente en las consultas médicas, el sordo pierde su derecho a la intimidad, cuando se ve obligado a asistir en compañía de un traductor. En virtud de esto, se determinó que el caso de estudio para el desarrollo y la validación de este sistema se orientaría hacia una consulta de medicina general.
Este documento describe el proceso de desarrollo de una aplicación móvil orientada a favorecer la comunicación entre sordos y oyentes, lo que repercutirá de manera positiva en el bienestar comunicativo de las dos poblaciones; para esto, se llevó a cabo una búsqueda de sistemas similares con el propósito de determinar el aporte de la herramienta, en este sentido, aunque existe una gran variedad de sistemas con propósitos similares, es evidente que la comunicación entre sordos y oyentes es un problema que persiste en el contexto Colombiano, esta evaluación, permitió evidenciar algunas limitaciones en los sistemas actuales:
Como respuesta a la problemática identificada, se generó una aplicación móvil, orientada a favorecer el bienestar comunicativo y la interacción entre sordos y oyentes, por medio de un sistema que implementa técnicas de traducción automática y aprendizaje de máquina para la generación de señas, a partir de la voz.
En esta aplicación específica, se hace uso de técnicas de traducción automática basada en Corpus, la cual se lleva a cabo a través del análisis de una gran cantidad de muestras, que indican al sistema las características, tanto de la lengua de origen como de destino. Para hacer el tratamiento a esta información se emplearon modelos estadísticos, por medio de un tratamiento matemático, en el que se establece, la probabilidad de traducción de una palabra en otra; en este caso, es de gran importancia contar con corpus de gran tamaño, se habla de un mínimo de dos (2) millones de palabras (Hernández M. y Gómez J., 2013).
Esta técnica se basa en fundamentos teóricos de la información y las comunicaciones (canal ruidoso), así como de modelos estadísticos obtenidos del análisis del corpus paralelo empleado, a partir de esto, es posible describir el modelo del canal ruidosos para esta aplicación como se presenta a continuación:
Ecuación 1: Modelo de canal ruidoso del sistema
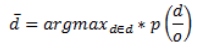
El modelo del canal ruidoso establece que, en un proceso de comunicación, un mensaje recibido puede diferir del mensaje enviado a causa del ruido que interfiere; en virtud de esto, lo que se busca es encontrar la mayor probabilidad de que los mensajes se correspondan.
Básicamente el proceso traducción consiste en determinar la mayor probabilidad que una secuencia de palabras en el idioma destino (d) correspondan a la traducción de la secuencia en la alengua origen (o), como se presenta en la Ecuación 1. Al aplicar el teorema de Bayes la expresión se transforma así:
Ecuación 2: Aplicación del teorema de Bayes
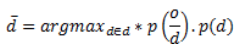
A partir de la Ecuación 2, es posible identificar la máxima probabilidad de que una frase en el lenguaje de destino, sea la traducción de una frase en el lenguaje de origen; para esto, por medio de la implementación del Teorema de Bayes, fue posible expresar la probabilidad de la Ecuación 1, por medio del producto del modelo de traducción expresado como la probabilidad de que una frase sea la traducción de otra P(o/d), por el modelo del lenguaje, expresado como la identificación de las frases más probables p(d).
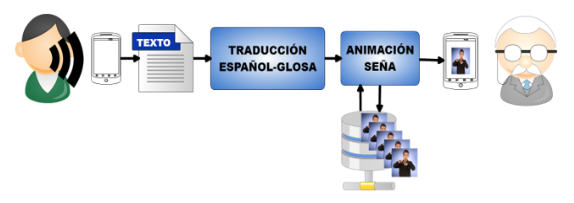
Como resultado de la aplicación de estos conceptos, se desarrolló una aplicación que permite que el usuario oyente exprese en voz alta la información que desea transmitir, el sistema convierte esta información inicialmente a texto, el cual es procesado por el algoritmo de traducción con el propósito de generar la GLOSA (Sistema de notación para la alengua de señas) equivalente y, a partir de esto, selecciona las seña correspondientes, las cuales son presentadas al usuario sordo en un dispositivo móvil. La Figura 1, ilustra el proceso descrito.
Figura 1
Descripción del sistema
Para este desarrollo el sistema se abordó como un problema de traducción convencional, teniendo como lengua de origen el español y como lengua de destino la Glosa Colombiana equivalente; para esto se determinó que el proceso más adecuado es la traducción basada en corpus, la cual se lleva a cabo a través del análisis de una gran cantidad de muestras, que indican al sistema las características, tanto de la lengua de origen como de destino. Para hacer el tratamiento a esta información, normalmente se emplean modelos estadísticos; en este caso, el análisis del corpus, se lleva a cabo por medio de un tratamiento matemático, en el que se establece, la probabilidad de traducción de una palabra en otra (Hohendahl, 2011).
En virtud de lo anterior, el primer paso de este desarrollo consistió en la generación de un corpus que brinde al sistema, los recursos necesarios para llevar a cabo la traducción de español a glosa colombiana y posteriormente, la generación de las señas correspondientes. Para esto se contó con el apoyo de una profesional en el uso de la glosa y la lengua de señas colombiana quien, con su experiencia, generó las oraciones requeridas en glosa colombiana.
Como resultado de este proceso se generaron tres (3) corpus: Corpus de preparación, de entrenamiento y de sintonización; los cuales serán usados de diversas maneras en el proceso, como se puede observar en la Figura 2.
Figura 2
Procedimiento de traducción llevado a cabo
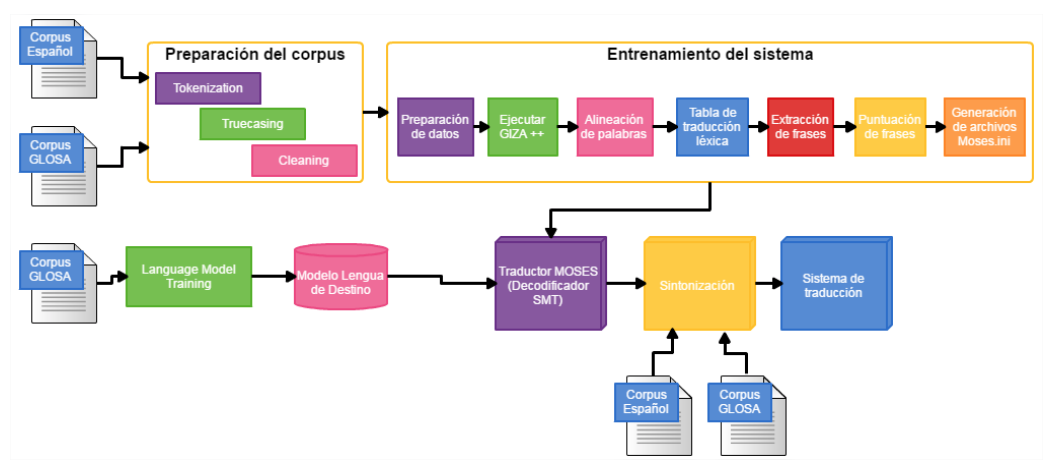
La Figura 2, también presenta los pasos que se siguieron para llevar a cabo la traducción y lograr el cumplimiento de los objetivos del proyecto:
a) Preparación del Corpus:
1. Tokenisation: En este proceso se generan espacios entre las palabras del corpus y los signos de puntuación, con el propósito de distinguir los signos de puntuación de las palabras.
2. Truecasing: Permite identificar las palabras que tienen inicial mayúscula y evitar que estas produzcan errores durante la traducción
3. Cleaning: En este proceso se eliminan oraciones demasiado largas (dependiendo de la configuración establecida) y líneas en blanco en el corpus, pues estas pueden causar problemas.
Una vez se ha completado la “limpieza” del corpus, se da inicio a la etapa de entrenamiento del sistema, para generar el modelo de la lengua de destino; al igual que en el numeral anterior, este procedimiento, se lleva a cabo por medio de scripts proporcionados por la herramienta MOSES.
b) Entrenamiento del Sistema
Se construye el modelo de lengua de destino con el propósito de asegurar una traducción más confiable, teniendo en cuenta las características de la lengua de destino.
En este caso se hace uso del modelo KEN-LM, el cual permite generar el modelo del lenguaje a partir de algoritmos estadísticos; para esto, es necesario realizar la configuración del sistema, con el propósito de definir los parámetros con los que se genera el modelo.
A partir del corpus generado en el proceso anterior y por medio de la instrucción para ejecutar KEN-LM, se genera un nuevo archivo en el que se presenta el modelo de la lengua de destino, en un formato reconocido por MOSES, para su posterior procesamiento en el proceso de traducción.
En estas dos etapas, a saber: preparación del corpus y entrenamiento del sistema, se está llevando a cabo la primera parte del proceso descrito en la Ecuación 2; es decir, se obtiene el modelo de la traducción, mientras que en la etapa que se describe a continuación, se genera el modelo del lenguaje.
c) Generar Modelo del lenguaje
Por medio de este proceso se toma el corpus paralelo y se genera un archivo de vocabulario; este archivo tiene cada una de las palabras del corpus, le asigna un identificador y establece el número de veces que aparece en el corpus; Posteriormente, se lleva a cabo la Alineación con la herramienta GIZA ++: En este procedimiento, se da como resultado un archivo en el que se determina de manera explícita la correspondencia que hay entre cada una de las palabras del corpus de lengua de origen con el de lengua de destino.
El siguiente paso es obtener la traducción léxica y hacer la extracción de las frases, la cual permitirá llevar a cabo la generación de un archivo que contiene una tabla de ponderaciones de traducción de cada una de las frases así: Probabilidad de traducción inversa de la frase j(d | o), Ponderación lexical inversa lex (d | o), Probabilidad de traducción directa de la frase j(o | d) y Ponderación lexical directa lex j(o | d).
Una vez ejecutado este proceso, el sistema se encuentra listo para dar inicio a las traducciones.
Tras la implementación de cada uno de los pasos descritos en el proceso anterior, se determinó la validez del sistema de traducción, por medio de la realización de diferentes pruebas, cuyos resultados se muestran a continuación:
Esta prueba está relacionada con la velocidad en la que el sistema genera la seña para cada palabra de la GLOSA generada, para esto, se tomaron frases pre determinadas y, se midió el tiempo que tardaba en generarse la seña en cada caso.
Se presentaron variaciones bastante marcadas, asociadas a la disponibilidad de la seña correspondiente a la palabra, en la base de datos; de modo que, si la seña de una palabra no se encuentra allí, el sistema extraerá de la base de datos, la seña de cada letra que compone cada una de las palabras de la frase, lo cual, desemboca en un mayor consumo de tiempo.
En virtud de lo anterior, no sorprende que los resultados de esta prueba evidencien una demora importante en el desempeño del sistema, sumado al hecho de que el sistema debe buscar en el servidor cada una de las señas y, en caso de no encontrar la seña, debe buscar la seña de cada una de las letras que componen la palabra, para deletrearla.
En este caso, con ayuda de la experta en GLOSA y lengua de señas, se seleccionaron 20 frases no incluidas en el corpus original y fueron traducidas en el sistema. El propósito de esta prueba es el de determinar si la traducción es adecuada, incluso con frases que se encuentran fuera de los archivos de entrenamiento del sistema.
Esta prueba representa la percepción real, que los usuarios de la aplicación pueden tener, respecto a la funcionalidad del sistema; el resultado de las traducciones en general fue bastante acertado, con un promedio de aceptación por parte del experto de un 85%; pese a este gran número de éxitos, se presentaron algunos casos en los que se evidenciaron errores graves en la traducción, a tal punto que las frases eran totalmente incomprensibles para un usuario sordo. A continuación, la Figura 3 presenta algunos de los resultados de la traducción, antes de ser presentados en la aplicación:
Figura 3
Resultados de traducción
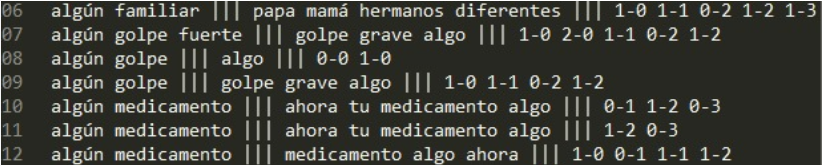
La Figura 3, permite evidenciar que, para una misma frase, el sistema es capaz de generar varias traducciones, a partir del entrenamiento recibido y de la conformación del CORPUS.
El análisis de estos resultados, permitió identificar que la aparición de errores está relacionada con la incapacidad del sistema de traducir palabras específicas; esto puede pasar en el marco de dos escenarios:
- El corpus no incluye todas las palabras, por esta razón, cuando el sistema ejecuta los algoritmos, no puede encontrar una traducción probable, lo que lo lleva a poner en la traducción la misma palabra.
- El algoritmo de cálculo de la traducción más probable, tiene un porcentaje de error, en el que la traducción más probable, no es la traducción adecuada.
Cualquiera de las dos situaciones, son previsibles teniendo en cuenta los resultados obtenidos en estudios y aplicaciones encontradas en la literatura, de hecho, un ejemplo claro de esto, se presentan en (Cognitive Computation Group, 2016), en dónde la traducción más probable no corresponde con la más adecuada.
Adicionalmente, se debe tener en cuenta que, dado el contexto donde se realizó la prueba, los algoritmos implementados no siempre pueden generar una traducción adecuada, debido a que algunas palabras son demasiado técnicas o específicas, por ejemplo, determinada patología, cierto medicamento o procedimiento, cuyos nombres no solo no tienen una traducción específica en GLOSA, sino que el debido a que no se encuentran en el corpus, el sistema no puede asociarlos a ningún grupo de palabras que conduzcan al entendimiento de la palabra.
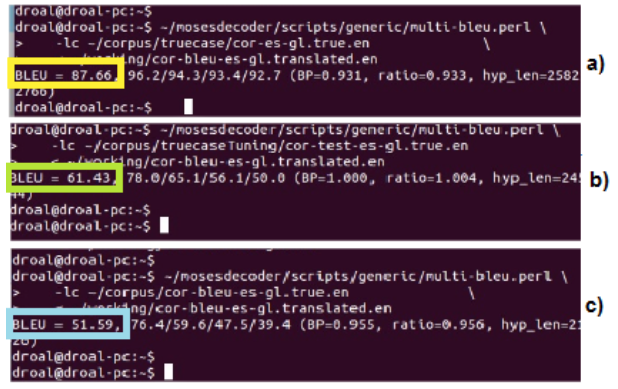
Finalmente, se llevó a cabo la prueba para determinar el desempeño del sistema. Esta prueba, no solo se concentró el identificar un porcentaje de calidad de la traducción, sino que, estuvo orientada a validar la teoría alrededor de la obtención del parámetro BLEU, el cual, por medio de un procesamiento interno, permite dar razón de la efectividad del sistema en virtud de la configuración del mismo. Para esta prueba se usaron tres (3) corpus, con el propósito de identificar la efectividad del sistema en diferentes escenarios:
1. BLEU obtenido usando como corpus de prueba, el corpus que se usó para el entrenamiento del sistema, con 603 frases: en este caso se obtuvo un parámetro de calidad de traducción de 87.66%, lo cual tiene perfecto sentido, porque el corpus empleado para la validación era totalmente conocido por el sistema, razón por la cual, se generaron traducciones muy cercanas a las de referencia.
2. BLEU obtenido usando como corpus de prueba el corpus de sintonización, con 50 frases: se obtuvo un parámetro de calidad de traducción de 61.43%, debido a que el pese a que el corpus era conocido, la mayoría de los parámetros de traducción surgen del procesamiento y análisis de las 603 frases del corpus de entrenamiento, lo que agrega elementos adicionales y hace que la traducción tenga variaciones.
3. BLEU obtenido usando como corpus de prueba, un corpus totalmente desconocido para el sistema, con 50 frases: Al igual que en el caso anterior, el análisis que genera las probabilidades de traducción se lleva a cabo con 653 frases, diferentes a la del corpus de prueba; sin embargo, en este caso se obtiene un parámetro de calidad de 51.59%, el cual es bastante alto, teniendo en cuenta que la GLOSA colombiana carece de estructura definida; sumado al hecho de que dado el contexto seleccionado, existe un gran número de palabras que no pueden ser traducidas.
La figura 4, permite evidenciar la variación del parámetro BLEU en cada uno de los casos descritos previamente
Figura 4
Prueba de parámetro BLEU
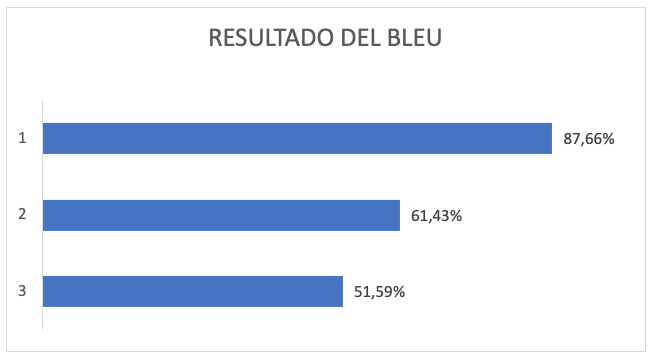
Pese a que el parámetro BLEU, a simple vista parece ser bajo, se encuentra dentro del rango, en comparación con valor obtenido en otros estudios encontrados en la literatura y que, emplean técnicas de traducción similares, lo que representa una respuesta muy positiva en el desarrollo de este proyecto. La Figura 5, permite evidenciar los resultados de este análisis sobre la plataforma desarrollada.
No obstante, el parámetro BLEU es adecuado, se considera que aún es posible realizar mejoras a los procesos que se llevaron a cabo en este proyecto, con el propósito de perfeccionar la traducción y brindar un sistema más eficiente a los usuarios de la Lengua de Señas Colombiana.
Figura 5
Resultados de evaluación de parámetro BLEU
Como resultado de la ejecución de este proyecto, se obtuvo un sistema de mediación comunicativa (como el mostrado en la Figura 4), el cual, provee al usuario de una interfaz en un dispositivo móvil, por medio de esta el usuario oyente ingresa un mensaje en voz alta, este es convertido a texto por la aplicación y traducido a GLOSA y a lengua de señas colombiana.
Figura 6
Interfaz de la aplicación resultante

La limitación del sistema a un caso de consulta de medicina general, facilitó el proceso de validación limitando la variedad de palabras que pudieran surgir; asimismo, esta selección permitió validar, la respuesta del sistema, frente a palabras totalmente desconocidas y sin traducción aparente, como el nombre de medicamentos o algunas patologías específicas que no se incluyeron en el corpus.
Por otra parte, en el desarrollo de este proyecto, se descubrió que, el componente facial y gestual de las señas generadas por los sordos, difícilmente sería reproducido por un “avatar”, lo que coincide con la opinión de la gran mayoría de los sujetos de la población sorda que participaron en la validación de este sistema; por esta razón, se determinó que la aplicación presentaría el vídeo de un sordo haciendo la seña correspondiente a cada una de las palabras pertenecientes a la glosa; asimismo, en el caso de que no se tenga el vídeo de una seña específica, el sistema presentará el vídeo de la seña de cada una de las letras que componen dicha palabra.
Proyectos de esta naturaleza favorecen significativamente el bienestar comunicativo de la población sorda, sumado a ello permite mayor independencia y autonomía a dicha población, no obstante, es importante precisar que aún se requiere incrementar el apoyo interdisciplinario para continuar con propuestas investigativas en esta misma línea.
El desarrollo de este proyecto, evidenció que los sistemas de traducción automática aún tienen muchos aspectos por mejorar y muchos retos que afrontar; sin embargo, en la revisión de la literatura y el análisis de las tecnologías disponibles, se evidenció que existen muchas herramientas de código abierto disponibles para apoyar este tipo de desarrollos y continuar con las labores investigativas en este campo.
Alonso, J. A. (2003). La traducción automática. En M. A. Martí (Ed.), Tecnologías del lenguaje (pp. 94-129). Barcelona: Editorial UOC.
Andrés T. H. (2011). Procesamiento de Lenguaje Natural Robusto. Recuperado de https://www.researchgate.net/publication/257111425_Procesamiento_de_Lenguaje_Natural_Robusto
Asociación para la normalización del lenguaje de signos. (2016). Signslator. Recuperado de http://singslator.net/traductor
Augusto C. V., Hugo V. H., Jaime P. Q. (2009). Procesamiento de lenguaje natural. vol. 6, N.º2, Julio - Diciembre 2009
Cuervo, C.E. (1998). La profesión de fonoaudiología: Colombia en perspectiva internacional. Universidad Nacional de Colombia. Bogotá, Colombia
Cortez Vásquez Augusto, Vega Huerta Hugo, Pariona Quispe Jaime (2009). Procesamiento de lenguaje natural. Revista de Ingeniería de Sistemas e Informática vol. 6, N.º 2.
Fillmore, charles J. y Beryl T. atkins, 1992: “Toward a frame-based lexicon: the semantics of RisK and its neighbors” en Adrienne lehrer y eva Feder kittay (ed.): Frames, fields, and contrasts, Hillsdale: lawrence, 75-102.
F. J. Martin Mateos J. L. Ruiz Reina (2013) Inteligencia Artificial II - Procesamiento del lenguaje natural. Dpto. Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla.
Fundación HETAH. (2016). Deletreado de palabras en HETAH. Recuperado de http://hetah.net/traductor
Galicia, S. (2000). Análisis sintáctico conducido por un diccionario de patrones de manejo sintáctico para lenguaje español. Tesis Doctoral del Instituto Politécnico Nacional, México.
Gelbukh and Bolshakov (1999), Avances en Análisis Automático de Textos. Proc. Foro: Computación, de la Teoría a la Práctica. IPN, M exico City, May 26 – 28, 1999.
Halvorsen, Per-Kristian, 1988: “computer applications of linguistic theory” en Frederick newmeyer (ed.): Linguistics: the Cambridge survey II. Linguistic theory: extensions and implications, cambridge: cambridge university Press, 198-219
Hanks, Patrick, 2003: “lexicography” en Ruslan mitkov (ed.): The Oxford handbook of computational linguistics, oxford: oxford university Press, 48-69.
Hernández M. y Gómez J. (2013). Aplicaciones de Procesamiento de Lenguaje Natural. Revista Politécnica. (Vol. 32, p. 96)
Icommunicator. (2017). iCommunicator: Assistive Technology for People who are Deaf. Recuperado de https://www.youtube.com/watch?v=2SFaUu5eUcE
Liddy, elizabeth D (2001): “natural language processing” en Encyclopedia of library and information science, segunda edición, nueva York: marcel Decker.
Martin Mateos, F.J. y Ruiz Reina, J.L. (2013). Inteligencia Artificial II. Dpto. Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla
Moure, Teresa y Joaquim llisterri, 1996: “lenguaje y nuevas tecnologías: el campo de la lingüística computacional” en milagros fernández Pérez (ed.): Avances en lingüística aplicada, santiago de compostela: universidad de santiago de compostela, 147-227.
PPRInc. (2016). Icommunicator. Recuperado de ttp://www.icommunicator.com/index.html
S. J. Raudys and A. K. Jain, (1991) “Small Sample Size Effects in Statistical Pattern Recognition: Recommendations for Practitioners”, in IEEE Transactions on Pattern Anaysis and Machine Intelligence, vol. 13, NO. 3.
S.Tan, X. Cheng, M. Ghanem, B,Wang, . and H. Xu (2005). “A novel refinement approach for text Categorization”, CIKM. 2005, pp. 469-476.
Zamorano, J. (2000) “La morfología verbal del español y la generación automática”. En: Procesamiento del Lenguaje Natural, No. 28. pp. 35-43.
Zapata Jaramillo Carlos Mario (2005). Los modelos verbales en lenguaje natural y su utilización en la elaboración de esquemas conceptuales para el desarrollo de software: una revisión crítica. REVISTA Universidad EAFIT. Vol. 41. No. 137 | enero, febrero, marzo 2005 .
1. Vicerrectoría de Investigaciones. Universidad Manuela Beltrán. Ingeniero Electrónico. Email: dario.rodriguez@umb.edu.co
2. Vicerrectoría de Investigaciones. Universidad Manuela Beltrán. Ingeniero Electrónico. Email: alejandra.rojas@umb.edu.co
3. Vicerrectoría de Investigaciones. Universidad Manuela Beltrán. Fonoaudióloga. Email: ana.vega@umb.edu.co