![]() ISSN 0798 1015
ISSN 0798 1015

![]() ISSN 0798 1015
ISSN 0798 1015
Vol. 39 (Nº 11) Año 2018. Pág. 2
Elkin Darío AGUIRRE Mesa 1; Héctor Sahir TABORDA Vargas 2; David Alberto GARCÍA Arango 3; Safiah Binti SIDEK 4
Recibido: 04/11/2017 • Aprobado: 25/11/2017
RESUMEN: Se exponen resultados obtenidos a partir de la implementación de procesos matemáticos al desarrollar un software que, mediante algoritmos para procesamiento digital de imágenes de alto nivel, realice la extracción de características fundamentales de una imagen de huella de mordida y luego las almacene en una tabla de resultados. Se emplearon técnicas sofisticadas de procesamiento de imágenes en diferentes etapas. |
ABSTRACT: Results obtained from the implementation of mathematical processes are presented when developing a software that, through algorithms for digital processing of high level images, performs the extraction of fundamental characteristics of a bite print image and then stores them in a table of results. Sophisticated image processing techniques were used at different stages. |

La Huella de Mordida es una de las Técnicas de Identificación comúnmente usada para establecer la identidad de las personas generalmente en el área policial.
Los sistemas de identificación basados en Huellas de Mordida actuales hacen uso de un dogma central en su análisis basado en dos suposiciones: Primero que la dentadura humana es única (exclusiva de cada individuo) y segundo que hay suficientes características diferenciadoras entre ellas que posibilitan una identificación. Los dientes son las estructuras más duras del cuerpo humano permaneciendo inalterables al paso del tiempo, lo cual hace posible un proceso de identificación por el altísimo número de combinaciones de características presentes en ellos: Posición de las piezas en la arcada dental, (Arango D. et al., 2017) ausencia de piezas, tratamientos de ortodoncia, entre otras. Dichas características son utilizadas por expertos para el reconocimiento de un individuo.
En la actualidad existe Software cuyos algoritmos para el reconocimiento automático de huellas de mordida tienen una eficiencia aproximada del 90%, pero que tienen un alto costo computacional, alta sensibilidad al ruido de la imagen y solo consideran información particular de la huella dejando de lado información mucho más global que se presenta, por lo cual, solo lo utilizan como apoyo a otras pruebas de mayor fiabilidad. Por consiguiente, surge una necesidad de explorar nuevas representaciones de huellas de mordida basadas principalmente desde la perspectiva del Procesamiento Digital de las Imágenes, la Visión Computacional y el reconocimiento de patrones.
La presente investigación pretende generar un Impacto a nivel académico y social con miras a plantear alternativas en el campo de la Ingeniería del Software y la Identificación de Personas; además que genera apropiación de conocimiento, buscando nuevas técnicas y procedimientos en el Procesamiento Digital de Imágenes (PDI) cuyo desarrollo tecnológico ha logrado que sus aplicaciones se extiendan también a muy diversas áreas como la medicina, monitoreo remoto, reconocimiento de objetos, visión por computador, manipulación de fotografías, entre otros.
La identificación de personas a través de las huellas de mordida es un tema que se trata a nivel general, pero no siempre desde un enfoque Tecnológico y con un uso de herramientas PDI, es una tarea que se ha venido desarrollando lenta y paulatinamente a través de técnicas mecánicas y manuales, apoyándose en procedimientos que requieren muestras en Alginato o Yeso de las piezas dentales de las personas, material fotográfico y radiografías y en las que no se incorpora o maneja procedimientos estándares de Procesamiento Digital de Imágenes.
El trabajo presentado en este artículo utiliza un análisis de las huellas de mordida como patrones de texturas orientadas, desde donde se extraen características invariantes combinando la información discriminatoria global y particular de una imagen. Se presenta la aplicación de esta representación para la implementación de un sistema de Identificación mediante huellas de mordida compuesto de varias etapas de procesamiento, (García A, et al., 2017) entre las que tenemos principalmente la extracción de características, su clasificación y posterior almacenamiento en Base de Datos.
En la etapa de extracción de características se obtiene una tabla de resultados denominada tbl_caracteristica cuyos valores representan la Huella de mordida. En la etapa de clasificación la tbl_caracteristica obtenida en la etapa anterior, almacena 5 características básicas, a partir de las cuales se generarán otros elementos característicos mediante procesos matemáticos que complementan ésta etapa. La siguiente etapa, denominada de coincidencia (Fase 2 del Proyecto), hará uso de procesos matemáticos como la distancia Euclidiana para determinar el grado de similitud que existe entre la tbl_caracteristica con el conjunto de tbl_caracteristica que se ingresa desde una imagen a comparar, buscando un alto grado de coincidencia pensando en la identificación de una persona a través de su huella de mordida.
Se emplearon Técnicas de procesamiento de Imágenes en diferentes etapas. Primero, toma y estandarización de imágenes, garantizando cálculos confiables. Segundo, extracción de características mediante una separación de canales en escala de grises, para localizar el centroide de cada pieza dental a través de técnicas de segmentación utilizando binarización, llenado de huecos y separación de objetos. Realizados estos pasos se obtuvo una representación gráfica de la huella, que se utilizará en fases siguientes de esta investigación. Los resultados se reflejan en el Desarrollo de la Aplicación, que incluye diferentes Técnicas de Procesamiento Digital de Imágenes que realizan valoración analítica de características que pueden extraerse de una imagen digital, deduciendo parámetros dimensionales y morfológicos en tiempo real del proceso de identificación. Investigaciones previas utilizan aplicaciones enfocadas al uso de parámetros geométricos de modelos tridimensionales. En conclusión, el Desarrollo de esta aplicación basada en el análisis de imágenes bidimensionales (2D) y el uso de PDI de alto Nivel utilizando procesos matemáticos orientados a producir una técnica adecuada para la identificación de una persona apoya la toma de decisiones correctas en este ámbito, en especial si se considera que actualmente no es común el uso de este tipo de herramientas para tal fin.
En el esquema propuesto de texturas orientadas primero se estandariza la imagen a una resolución de 3000 x 2000 para que las diferentes mediciones y cálculos a realizar sean lo más fiable posible en el momento de la comparación. Una vez estandarizada la imagen RGB, se realiza una división de canales (Split channels) en tres imágenes de escala de grises de 8 bits que contienen los componentes rojo, verde y azul de la original, entre las cuales de manera experimental por ser la que mejor calidad y definición muestra se escoge la verde (Green) para su procesamiento. Luego, de manera automática se colocan valores de límites superior e inferior (Thresholding) (González R, Woods R. 2002) para segmentar la imagen en escala de grises dentro de las características de mayor interés y de fondo. Seguidamente se convierte la imagen a blanco y negro (Make binary) y se rellenan los huecos (Fill Holes) que en ella queden para darle uniformidad a la textura y poder aplicarle una segmentación especial (Watershed) que separa automáticamente las partículas que se tocan, dando la forma final a la imagen que se busca (Huella de Mordida).
Los pasos principales para la extracción de características se profundizan a continuación:
Una imagen es considerada una función bidimensional descrita en forma matricial como (ecuación 1):
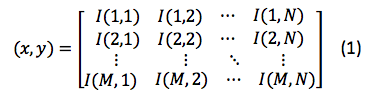
Donde los subíndices x, y representan los desplazamientos en forma horizontal y vertical (filas y columnas), así como M y N representan las dimensiones de la imagen. La forma de representar imágenes plantea una adaptación del modelo descrito en la ecuación (1) respecto a la manera de indexar los datos matricialmente, esto significa que los índices intercambian posiciones, con lo anterior es posible adoptar la notación matricial típica de renglón-columna.
Una imagen a escala de grises es una matriz cuyos valores han sido escalados para representar un determinado número de intervalos. Si la imagen es del tipo 8-bit entonces los datos que la conforman se encuentran en el intervalo [0,255]. Si la imagen es del tipo double, entonces los datos que la constituyen son del tipo flotante y se encuentran en el intervalo [0,1].
Una imagen binaria del tipo logical se representa como un arreglo que solo contienen unos y ceros. Estos ceros y unos son especiales, porque no implican valores numéricos, sino más bien banderas que indican el estado de falso (0) o verdadero (1).
El modelo de color RGB (González &, Wood, 2004), se basa en la combinación de los colores primarios rojo (R), verde (G) y azul (B). El origen de este modelo se encuentra en la tecnología de la televisión y puede ser considerado como la representación fundamental del color en las computadoras, cámaras digitales y escáneres, así como en el almacenamiento de imágenes. La mayoría de los programas para el procesamiento de imágenes y de representación gráfica utilizan este modelo para la representación interna del color. El modelo RGB (Cuevas, Zaldivar y Pérez, 2010) es un formato de color aditivo, lo que significa que la combinación de colores se basa en la adición de los componentes individuales considerando como base el negro. Este proceso puede imaginarse como el traslape de 3 rayos de luz de colores rojo, verde y azul, los cuales son dirigidos hacia una hoja de papel blanca, y cuya intensidad puede ser continuamente controlada. La intensidad de los diferentes componentes de color determina tanto el tono como la iluminación de color resultante. El blanco y el gris o tonalidades de gris son producidos de igual manera a través de la combinación de los tres correspondientes colores primarios RGB.
El modelo RGB forma un cubo, cuyos ejes de coordenadas corresponden a los 3 colores primarios R, G y B. Los valores RGB son positivos y sus valores se encuentran restringidos al intervalo de [0, V_max], (Cuevas, Zaldivar, y Pérez, 2010) en donde normalmente V_max=255. Cada posible color C, corresponde a un punto dentro del cubo RGB, con las componentes:
C_1=(R_i,G_i,B_i )
Donde 0≤R_i,G_i,B_i≤V_max. Normalmente el intervalo de valores de los componentes de color son normalizados al intervalo [0,1], de tal forma que el espacio de colores quedaría representado por el cubo unitario. El punto N=(0,0,0) corresponde al negro, W=(1,1,1) corresponde al blanco y todos los puntos que se encuentren en la línea entre S y W son las tonalidades a escala de grises donde las componentes R, G y B son iguales.
Desde el punto de vista del Software una imagen a color RGB es un arreglo de tamaño M×N×3, donde M×N define las dimensiones de los planos mientras que la dimensión correspondiente a 3 define a cada uno de ellos R, G y B. atendiendo a lo anterior, una imagen RGB puede considerarse como un arreglo de 3 imágenes a escala de grises.
Fig. 1
Imagen Original.

Elaboración de los autores
-----
Fig. 2
Imagen Estándar (3000 x 2000)

Elaboración de los autores
3.1.2. División de Canales (Split Channels):
La conversión de una imagen RGB a escala de grises se realiza a través del cálculo que resulta de considerar un equivalente E formado entre los valores contenidos en cada plano del color que lo constituyen. En su forma más sencilla podría establecerse este equivalente como el promedio de los valores de los tres componentes de color, tal que:
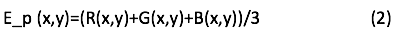
La subjetiva iluminación, propia del modelo RGB, hace que imágenes con un valor grande en la componente de rojo y/o verde tengan una apariencia obscura (en la imagen a escala de grises convertida mediante la ecuación (2)). El efecto contrario sucede en aquellos pixeles donde el contenido del plano azul es grande, mostrando en su versión a escala de grises una apariencia más clara. Con el objetivo de solventar este problema se considera como una mejor aproximación a la ecuación (2) el calcular una combinación lineal de todos los planos, definida como:

Donde w_R,w_G,y w_B son los coeficientes que definen la transformación, los cuales de acuerdo al criterio utilizado en la TV para señales a color (Efford, 2010), se consideran como:

Siendo formales la ecuación (2) puede ser considerada como un caso especial de la ecuación (3).
Una vez en escala de grises, se realiza la división de canales en tres imágenes de 8 bits que contienen los componentes rojo, verde y azul de la original
Fig. 3
Canal Rojo

Elaboración de los autores
----
Fig. 4
Canal Verde

Elaboración de los autores
-----
Fig. 5
Canal Azul

Elaboración de los autores
3.1.3. Segmentación por Umbral:
La segmentación por la utilización de un umbral puede ser considerada como una forma especial de cuantificación en la cual los pixeles de la imagen son divididos en dos clases, dependiendo de un umbral (“Threshold”) predefinido PTH, que se basa en la hipótesis de que existe un valor umbral bajo/sobre el cual puede diferenciarse a la imagen en cuestión del fondo. Este algoritmo ideado por Otsu en 1979 (Bovik, 2009), tiene un formulismo matemático planteado a continuación:

Siendo k la posición índice del histograma en el rango de niveles de gris (de 0 a 255 niveles, si se emplean 8 bits en la codificación).
Siendo p el valor normalizado del histograma para la posición actual indexada.
Siendo w y µ los valores acumulativos de primer y segundo orden del histograma normalizado.
Siendo µT el nivel medio total de la imagen.
Fig. 6
Threshold configurado

Elaboración de los autores
-----
Fig. 7
Threshold aplicado

Elaboración de los autores
3.1.4. Binarización
En este paso se plantea una reducción de información en la que los únicos valores posibles son verdadero y falso (1 y 0). En el caso de una imagen digital los valores verdadero y falso se corresponden a dos colores: blanco y negro (Chaira T. 2015). Mediante esta técnica se consigue separar los objetos o regiones de interés, del resto de la imagen. Es decir, que se puede separar el fondo de la imagen de la imagen de los objetos que deseamos analizar. En el proceso de binarización de la imagen se utiliza normalmente un umbral de la escala de grises para conocer qué es blanco y qué es negro. Las imágenes por lo general no se encuentran en una escala de grises, por lo que se debe calcular la tonalidad de gris durante el proceso.
El algoritmo utiliza también el Método de Otsu, el cual maximiza la probabilidad que el umbral que es elegido logra una separación de la imagen entre los objetos y su fondo. Esto se logra mediante la selección de un umbral que proporcione una mejor separación de clases, para todos los pixeles en la imagen (Fischler y Firshcein, 1987). La base de esta técnica es el uso del Histograma Normalizado, donde el número de puntos en cada nivel es dividido entre el número de puntos totales de la imagen. Así, la distribución de probabilidad de los niveles de intensidad está dada por:

Donde:
P(l)= Es la Distribución de Probabilidad
N(l)= Número de puntos por nivel de la Imagen nueva
N2= Puntos de entrada
Este método calcula la tonalidad de gris de cada pixel de la imagen de entrada, si la tonalidad de gris supera el umbral ese pixel será verdadero, es decir, un pixel blanco en la imagen destino, en caso contrario, el pixel será negro en la imagen destino. Para calcular la tonalidad de gris se realizará una media ponderada de los valores RGB, la media viene ponderada por la percepción humana de los colores debido a que somos más sensibles al verde y menos al azul (30% Rojo, 59% Verde, 11% Azul).
Fig. 8
Imagen Binarizada

Elaboración de los autores
3.1.5. Llenado de Huecos y Separación:
La acción de binarización se complementa con dos funciones especiales conocidas como Fill Holes (que utiliza un algoritmo de restauración de imágenes para reconstruir las partes que se han de completar) y Watershed. Fill holes llena agujeros en la imagen binaria (Fischler y Firshcein, 1987), definiendo un agujero como un conjunto de píxeles de fondo que no se pueden alcanzar rellenando el fondo desde el borde de la imagen; y la segmentación Watershed es una manera automática de separar o cortar partículas que se tocan en una imagen. Primero se calcula la distancia Euclidiana y se encuentran los últimos puntos erosionados, entonces se dilata cada uno de ellos tan lejos como sea posible hasta que se alcanza el borde de la partícula o el borde toca una región de otra.
La operación de relleno se basa en operaciones morfológicas que consisten en una secuencia de dilataciones, complementos e intersecciones. Dada una imagen de borde original como la imagen A de la figura, se obtiene una imagen Ac, que corresponde al complemento de la imagen A. Se define también un elemento estructurante B.
El proceso de relleno consiste en aplicar recursivamente la siguiente operación:

Se utiliza como punto de partida un punto al interior del objeto que se desea rellenar como muestra la imagen X0 y se realiza la operación dilatación con el elemento B. Esta dilatación expande la imagen en todas las direcciones. Sin embargo al realizar la intersección con la imagen AC, se logra mantener los puntos dilatados siempre dentro de los bordes de la imagen original. Este proceso se repite "n-veces" hasta que la imagen Xk sea idéntica a la imagen Xk-1. Es decir, hasta que no se generen nuevos cambios y el proceso se detenga.
Fig. 9
Dilatación y Erosión

Elaboración de los autores
La Técnica de Watershed (“Línea de División de aguas”) es una técnica de segmentación basada en morfología matemática, que permite extraer las fronteras de las regiones que hay en una imagen (Serna y Roman, 2009). A la vez, se considera una técnica de segmentación basada en regiones, debido a que clasifica los pixeles según su proximidad espacial, el gradiente de sus niveles de gris y la homogeneidad de sus texturas. Se considera la magnitud del gradiente de una imagen como una superficie topográfica. Los píxeles que tienen las más altas intensidades de gradiente corresponden a las líneas divisorias, que representan los límites de las regiones (Proakis & Manolakis, 1996). El agua puesta sobre cualquier píxel encerrado por una línea divisoria común fluye colina abajo a un mínimo de intensidad local común (Russ & Neal, 2016). Los píxeles que drenan a un mínimo común forman una cuenca, que representa un segmento de la imagen (un objeto).

Angulo del gradiente que apunta en su máxima dirección
Fig. 10
Imagen con Fill Holes

Elaboración de los autores
-----
Fig. 11
Imagen con segmentación Watershed

Elaboración de los autores
Las pruebas de los algoritmos que realizan los pasos descritos anteriormente fueron realizadas utilizando imágenes de impresiones dentales tomadas a usuarios de la IPS de la Universidad, previamente informados para dar su autorización. Dichas imágenes fueron tomadas con una Cámara Digital Profesional marca Nikon D5300 de 24.2 megapixeles, panalla LCD de 3.2”, velocidad mínima de obturación 1/4000 y Lente Nikon de 18-55 mm VR. Cada imagen se capturó desde una distancia perpendicular de 15 cm y fue seguidamente estandarizada de un tamaño inicial de 4000 x 3000 a uno de 3000 x 2000 con un algoritmo de redimensionamiento planteado en el software.
En el esquema implementado y de acuerdo a la complejidad de los algoritmos utilizados para discriminar la extracción de características de las imágenes de impresiones dentales se determinaron 5 características básicas: Número de piezas dentales, Área de cada pieza, Centroide (en función de coordenadas x, y) y el Perímetro.
Fig. 12
Extracción de Características de Piezas dentales

Elaboración de los autores
A partir de estos datos el Software genera una tabla denominada tbl_característica almacenada posteriormente en una Base de Datos, cuyos valores representan la Huella de mordida y con los cuales se espera iniciar una segunda etapa del desarrollo del software para realizar la comparación de imágenes e iniciar un proceso de identificación.
Se ha realizado el estudio e implementación de algoritmos eficientes en Java para el reconocimiento de imágenes de huellas de mordida y su posterior extracción de características, mostrando su robustez y eficiencia, así como algunos puntos débiles tales como la búsqueda de los estándares en la captura de las imágenes y los valores de configuración requeridos en cada una de las etapas para obtener óptimos resultados al momento de su ejecución.
El desarrollo de estos algoritmos otorga la búsqueda de nuevas alternativas y mejoras a los sistemas de identificación de personas basado en huellas de mordida, así como el estudio de técnicas flexibles y eficientes que permitan definir una metodología idónea en el desarrollo de Software para que los resultados en cuanto a rendimiento sean mucho más elevados.
Este proyecto se establece como base para desarrollar una herramienta más amplia (Segunda Fase) cuyo alcance será la Identificación de Personas a través de su Huella de Mordida.
Bovik A. (2009). The Essential Guide to Image Processing. USA: AP.
Chaira T. (2015). Medical Image Processing. Advanced Fuzzy Set Theoretic Techniques. New York: CRC Press,
Cuevas E.; Zaldivar D. y Perez M. (2010). Procesamiento Digital de Imágenes Con MatLab y Simulink. México, Alfa Omega
Efford N. (2000). Digital Image Processing: A Practical Introduction Using Java. England: Wesley Addison.
Fischler M.A. y Firshcein O. (1987). Intelligence, The Eye, The Brain and the Compute. Massachusetts: Addison Wesley
García, G., García, G., Gallego, D., Zapata, J., & Juidias, R. (2017). Impacto medioambiental de la integración de la computación en la nube y la Internet de las cosas. Producción+ Limpia, 11(2)
García, D., Mesa, E., & Quiceno, D. (2017). Medidas de riesgo en modelos de inventario: ¿determinismo o incertidumbre en la producción sustentable? Journal of Engineering and Technology, 6(1).
González, R. & Woods, R. (2002).Digital Image Processing, Prentice Hall. New Jersy: Upper Saddle River.
González, R. & Woods, R. (2004). Digital Image using MatLab Processing. USA: Pearson - Prentice Hall.
Serna, N. & Roman, U. (2009). Técnicas de Segmentación en Procesamiento Digital de Imágenes. Revista de Investigación de Sistemas e Informática (RISI), 6 (2).
Proakis J. & Manolakis, D. (1996). Digital Signal Processing, Principles, Algorithms, and Applications. Upper Saddle River, NJ: Prentice Hall.
Russ J.C. & Neal, F. (2016). The Image Processing Handbook. Seventh Edition. New York: CRC Press.
Zabaleta, M.; Brito, L. & Garzón, M. (2016). Modelo de gestión del conocimiento en el área de TIC para una universidad del caribe colombiano. Revista Lasallista de Investigación, 13(2), 136-150.
1. Magister en Gestión de la Tecnología Educativa, Universidad De Santander. Especialista en administración de la informática educativa, Universidad De Santander. Docente –Investigador Fundación Universitaria Autónoma de las Américas. Correo Electrónico: elkin.aguirre@uam.edu.co
2.Magister en Gestión de la Tecnología Educativa, Universidad De Santander. Especialista en administración de la informática educativa, Universidad De Santander. Docente –Investigador Fundación Universitaria Autónoma de las Américas. Correo Electrónico: hector.taborda@uam.edu.co
3. Magister en matemáticas aplicadas, Universidad Eafit. Docente de la Corporación Universitaria Americana. Sede Medellín. Correo Electrónico: dgarcia@coruniamericana.edu.co
4. Docente-Investigador Universiti Teknikal Malaysia Melaka (UTeM). Hang Tuah Jaya, 76100 Durian Tunggal, Melaka. safiahsidek@utem.edu.my