![]() ISSN 0798 1015
ISSN 0798 1015

![]() ISSN 0798 1015
ISSN 0798 1015
Vol. 39 (Nº 06) Año 2018. Pág. 19
Guillermo A. LÓPEZ Calvajar 1; Irán ALONSO HERNÁNDEZ 2; Zahily MAZAIRA RODRÍGUEZ 3; Henrry RICARDO CABRERA 4
Recibido: 03/10/2017 • Aprobado: 29/10/2017
RESUMEN: La presente investigación basada en el estudio de casos de una planta de producción de cemento tiene como objetivo determinar la confiabilidad operacional de los procesos productivos en la industria, se aplicó un procedimiento para la mejora de la disponibilidad técnica de procesos, empleando sistemas analíticos como herramienta para la mejora del trabajo de operadores, utilizando listas de chequeo elaboradas desde la identificación del aporte de la indisponibilidad del equipo al fallo del sistema tecnológico. De su aplicación se presentan los resultados en los sistemas tecnológicos de la cementera realizados sobre la base de la confiabilidad de sus componentes. |
ABSTRACT: The present investigation based on the case study of a cement production plant aims to determine the operational reliability of the production processes in the industry, for which a procedure was applied to improve the technical availability of processes using analytical systems as a tool for the improvement of the work of operators, using checklists elaborated from the identification of the contribution of the unavailability of the equipment to the failure of the technological system. From its application are presented the results in the technological systems of the cement manufacturer based on the reliability of its components. |

Con frecuencia, el concepto de instalación de proceso va asociado a un sistema productivo o a una parte de él, donde intervienen materias primas que a través de determinadas operaciones básicas, generalmente concatenadas, son sometidas a procesos físicos y/o químicos para obtener productos intermedios o acabados. Las instalaciones son diseñadas para adecuarse a las condiciones normales de trabajo, pero deben ser capaces de soportar alteraciones previsibles, aunque sean ocasionales, sin generar daños a personas y bienes.
Por la importancia que tiene la atención a los fallos de las instalaciones, fundamentalmente por el impacto en la eficiencia y eficacia de las empresas, específicamente en la producción de cemento, resultan pertinentes los estudios que se realicen para su mitigación.
El análisis operacional en instalaciones requiere considerar todas las variables que condicionan el proceso en cuestión, planteándose variaciones ante posibles fallos o deficiencias (Vaidas Matuzas & Sergio Contini, 2012) y, consecuentemente, la capacidad de respuesta de la instalación en base a sus características y a los elementos de operación, muchos de los cuales deben garantizar una respuesta activa. Las alteraciones que puedan aparecer son diversas, como diversas son sus causas y consecuencias, que necesariamente deben ser consideradas para poder efectuar una evaluación operacional de la instalación en complejos esquemas de interrelación secuencial (Dunnett & J.D. Andrews, 2004). Una peculiaridad destacable en las instalaciones de proceso es que suele existir interrelación entre la indisponibilidad del equipamiento y sus factores causales, que según las circunstancias desencadenantes generan diferentes niveles de fallos y de sus consecuencias (Nusbaumer & Rauzy, 2013).
Los métodos aplicados en los análisis operacionales para la confección de las listas de chequeo en la industria cementera, no consideran la fiabilidad de los componentes y, por ende, la frecuencia de revisión y los parámetros necesarios no toman en cuenta la contribución de dicho elemento al fallo de sistemas, situación que genera el problema de esta investigación, definido como la necesidad de identificar y disminuir las interrupciones y/o fallas ocasionadas en el proceso productivo de la empresa caso de estudio, que inciden en la disminución de la confiabilidad operacional y provocan cuantiosas pérdidas para la entidad, que lleva al estudio operacional de cada sistema tecnológico que requiere, ineludiblemente, de un trabajo en equipo formado por técnicos conocedores del proceso y funcionamiento de la instalación, y de un método que facilite la reflexión y el análisis en profundidad. El método propuesto en este trabajo permite analizar el peso operacional de cada componente del sistema tecnológico y trazar las estrategias para las revisiones tanto operacionales como de mantenimiento, con vistas a la mejorar operacional.
Para desarrollar el estudio se empleó el Árbol de Fallas como herramienta para detectar el aporte a la falla del sistema de cada componente de la instalación (Zheng Liu, Yan-Feng, Li-Ping He, & Hong-Zhong Huang, 2014) y así confeccionar las listas de Chequeo y con ello contribuir a mejorar el trabajo de los obreros de la instalación; además, se utilizaron técnicas y modelos de distribución estadísticos que facilitan una mejor utilización de los datos disponibles y que permiten tener una mayor confiabilidad para la toma de decisiones; además se tuvieron en cuenta las siete herramientas básicas del control estadístico y mejoramiento de la calidad.
Según las generalidades del árbol de fallas, un sistema consta de personas, equipo, material y factores ambientales. Este sistema realiza tareas específicas con métodos recomendados (Majdara & Wakabayashi, 2010). Los componentes de un sistema y su ambiente están interrelacionados y una falla en cualquier parte puede afectar las demás partes.
El Análisis por Árboles de Fallos (AAF), es una técnica deductiva que se centra en un suceso accidental particular (accidente) y proporciona un método para determinar las causas que han producido dicho accidente. Se trata de un método deductivo de análisis que parte de la previa selección de un suceso no deseado o evento que se pretende evitar, sea este un accidente de gran magnitud (explosión, fuga, derrame entre otras) o un suceso de menor importancia (fallo de un sistema de cierre) para averiguar en ambos casos los orígenes (Li, Si, Xing, & Sun, 2014).
Seguidamente, de manera sistemática y lógica, se representan las combinaciones de las situaciones que pueden dar lugar a la producción del “evento a evitar”, conformando niveles sucesivos de tal manera que cada suceso esté generado a partir de sucesos del nivel inferior, siendo el nexo de unión entre niveles la existencia de “operadores o puertas lógicas”. El árbol se desarrolla en sus distintas ramas hasta alcanzar una serie de “sucesos básicos”, denominados así porque no precisan de otros anteriores a ellos para ser explicados. También alguna rama puede terminar por alcanzar un “suceso no desarrollado” en otros, sea por falta de información o de análisis de las causas que lo producen.
El suceso iniciador puede ser cualquier desviación importante, provocada por un fallo de un equipo, error de operación o humano. Depende de las salvaguardias tecnológicas del sistema, de las circunstancias y de la reacción de los operadores, las consecuencias pueden ser muy diferentes. Por esta razón, está recomendado para sistemas que tienen establecidos procedimientos de seguridad y emergencia para responder a sucesos iniciadores específicos. Los nudos de las diferentes puertas y los “sucesos básicos o no desarrollados” deben estar claramente identificados.
Para ser eficaz, un análisis por árbol de fallos debe ser elaborado por personas profundamente conocedoras de la instalación o proceso a analizar y que a su vez conozcan el método y tengan experiencia en su aplicación; por lo que, si fuera preciso, se deberán constituir equipos de trabajo pluridisciplinarios (técnico de seguridad, ingeniero del proyecto, ingeniero de proceso, entre otros) para proceder a la reflexión conjunta que el método propicie. El análisis deducible empieza con una conclusión general, luego intenta determinar las causas específicas de la conclusión a partir de la construcción de un diagrama lógico llamado un árbol de falla (Hurdle, Bartlett, & J. D. Andrews, 2007).
El motivo principal del análisis de este árbol es el ayudar a identificar causas potenciales de falla de sistemas antes de que estas ocurran (Shneiderman, Dunne, Sharma, & Wang, 2012). También puede ser utilizado para evaluar la probabilidad del evento más alto utilizando métodos analíticos o estadísticos. Estos cálculos envuelven sistemas de relatividad cuantitativos e información de mantenimiento tales como probabilidad de falla, tarifa de falla, y tarifa de reparación. La ventaja principal de los análisis de árbol de falla son los datos valiosos que producen que permiten evaluar y mejorar la fiabilidad general del sistema (Contini &Matuzas, 2012). También evalúa la eficiencia y la necesidad de redundancia.
El desarrollo de procesos productivos conlleva al diseño de operaciones industriales, al empleo de máquinas, equipos y herramientas, así como la utilización de materias primas e insumos, lo cual modifica el ambiente natural del hombre y si bien facilita y aumenta la eficiencia del trabajo, también aporta factores de riesgo que es necesario controlar para evitar que los adelantos que deben constituirse en un aporte para el bienestar del hombre se conviertan en agresores de su integridad (Pérez, 2012).
Por lo anterior, se establecen diversos mecanismos conducentes al control de los riesgos. Las listas de chequeo constituyen uno de estos mecanismos y su función básica es la de detectar condiciones peligrosas que puedan generar accidentes o enfermedad profesional, antes que se desencadenen los accidentes o avancen las enfermedades profesionales.
Es de vital importancia entender qué es una lista de chequeo y cuál es su aplicabilidad, existen muchos formatos de listas de chequeo para diversas actividades o equipos, pero cada lista de chequeo debe ser particular, aunque el especialista se pueda basar en el modelo. Se entiende por lista de chequeo (chek-list) a un listado de preguntas, en forma de cuestionario, que sirve para verificar el grado de cumplimiento de determinas reglas establecidas con un fin determinado. Las preguntas en forma de cuestionario sirven como una guía, que obligan a quien las contesta a reflexionar sobre el nivel de acatamiento de determinados requisitos o reglas. La ckeck-list enumera una serie de ítems (muchos o pocos dependerá de la exhaustividad que se pretenda) que deberían verificarse uno a uno para asegurarnos de lograr el producto final con un nivel de calidad previamente aceptado.
Uno de los formatos más prácticos y fáciles de usar son aquellos diseñados en forma de cuadro, que permiten un llenado rápido de los distintos casilleros. Otra opción de diseño es un listado de preguntas con espacios libres al final, que deben ser respondidas con frases breves y sencillas por parte de aquellos encargados que realizan el control y también una combinación de ellas; pero como norma general es aconsejable un diseño sencillo, práctico y fácil de visualizar, de manera que quien responda se familiarice con la lista de manera rápida y la incorpore a su rutina de trabajo de manera natural. Las listas de chequeo tienen por lo general, más de un destinatario y usuario, pues sirven a quien realizó el trabajo para verificar que no olvidó el cumplimiento de ninguna regla (autocontrol o control interno) y también para quien deba revisar el trabajo de otros mediante estos listados, pues permite verificar de manera rápida el cumplimiento de las tareas planteadas (Pérez, 2012).
El procedimiento propuesto cuenta de cuatro etapas: Preparación, Diagnóstico, Análisis y Control y Optimización, las cuales cuentan con un sistema de actividades para su diseño y ejecución en las que se incluyen metodologías y herramientas de confiabilidad, cuyos resultados conducen a la empresa al mejoramiento continuo. A continuación, se presentan los resultados obtenidos de la confiabilidad operacional en la industria objeto de estudio.
Esta fase incluye acciones para asegurar el éxito de las etapas, formación y el compromiso desde la alta dirección hasta los niveles inferiores de la organización.
En este paso se crea el grupo de expertos, los cuales se relacionan con la actividad y ocupan los cargos de especialistas en operación, mantenimiento, jefes de área, supervisores y gerentes, cuyas habilidades se complementan entre sí, con vasto conocimiento del tema y se logra involucrar en el estudio a la alta dirección. Se realiza una sesión de trabajo reuniéndose el equipo, se induce la metodología y los representantes de las áreas como facilitadores de las sesiones de trabajo guían el estudio. El equipo de trabajo se conformó por: conductor del grupo, estudiantes de Ingeniería Industrial, coordinador de proceso y mejora continua y personal de operación.
Se recopila la información relativa a los equipos de todas las áreas, comenzando con un trabajo de preparación y registro de información técnica de cada equipo, funciones, parámetros de trabajo, sistemas, datos de fallas correspondientes al período de dos años.
El histórico de los equipos se registra desde el año 2004 y contempla la siguiente información: fecha de inicio de la parada, código del equipo, código de la parada, hora de inicio de la parada, hora de salida de la parada y comentario (motivo de la parada).
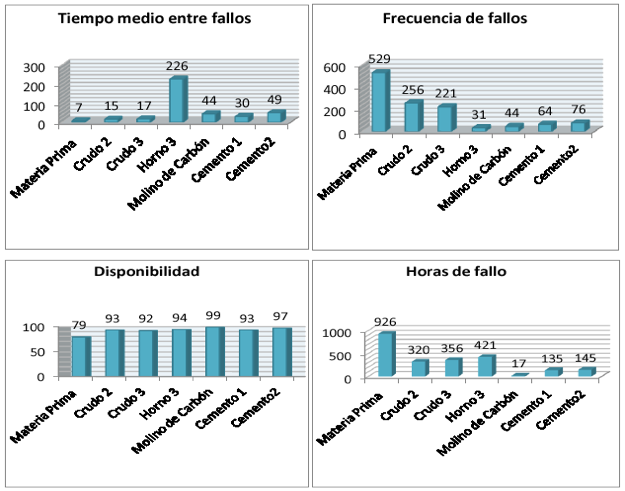
Selección del proceso o área: Los paros en los procesos se registran por causas como mantenimiento, falta de materia prima, acomodo, silos llenos o por averías y se clasifican según la causa que los origina en fallo eléctrico y de control, fallo mecánico y fallo de operación. En la figura 1 se presentan los indicadores disponibilidad, tiempo medio entre fallas, horas de fallas y cantidad de fallas en el año 2015 por áreas, localizándose en materias primas la situación más significativa con la menor disponibilidad y tiempo medio entre fallas, mayor número de fallas y horas de fallas, por lo que se decidió comenzar el estudio por esta área.
Figura 1
Comportamiento de los indicadores, Fuente: Elaboración de los autores
En este paso se realizó el análisis de criticidad en el área seleccionada, con el objetivo de establecer niveles de jerarquía en todos los equipos, de acuerdo a criterios previamente establecidos en una matriz que considera los parámetros operacionales, riesgos asociados a la operación, a la seguridad, al medio ambiente y a las fallas del equipo en el período que se analiza.
Tabla 1
Categorización por niveles de criticidad de los equipos
Código |
Nombre del equipo |
Clasificación |
ICsha |
ICp |
Fr. |
IGC |
Condición |
221-TP1 |
Transportador de placa |
Dinámico |
1 |
4 |
4 |
A144 |
Alta |
221-RD1 |
Rascador |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
221-CT1 |
Criba |
Dinámico |
1 |
4 |
1 |
B141 |
Media |
221-AE1 |
Alimentador |
Dinámico |
1 |
4 |
1 |
B141 |
Media |
211-TS1 |
Trituradora |
Dinámico |
1 |
3 |
3 |
B133 |
Media |
211-VE1 |
Ventilador de polvo |
Dinámico |
4 |
1 |
1 |
B411 |
Media |
221-BT1 |
Banda de material fino |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
221-BT2 |
Banda de material fino |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
291-BT1 |
Banda de material grueso |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
291-BT2 |
Banda |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
221-TP2 |
Transportador de placa |
Dinámico |
0 |
4 |
1 |
B141 |
Media |
221-BT4 |
Banda de hierro |
Dinámico |
0 |
2 |
2 |
C022 |
Baja |
221-BT3 |
Banda al secador |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
221-SE1 |
Secador |
Dinámico |
0 |
3 |
1 |
B031 |
Media |
221-VE1 |
Ventilador de polvo (Casa de polvo) |
Dinámico |
3 |
2 |
1 |
C321 |
Baja |
291-BT3 |
Banda |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
291-BT4 |
Banda |
Dinámico |
1 |
3 |
3 |
B133 |
Media |
291-BT5 |
Banda |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
291-BT6 |
Banda |
Dinámico |
1 |
3 |
2 |
B132 |
Media |
291-FT1 |
Filtro de manga |
Estático |
3 |
1 |
2 |
B132 |
Media |
291-FT2 |
Filtro de manga |
Estático |
3 |
1 |
2 |
B132 |
Media |
291-FT3 |
Filtro de manga |
Estático |
3 |
1 |
2 |
B132 |
Media |
291-FT4 |
Filtro de manga |
Estático |
3 |
1 |
2 |
B132 |
Media |
291-FT5 |
Filtro de manga |
Estático |
3 |
1 |
2 |
B132 |
Media |
Del análisis se obtuvo como resultado una categorización de los equipos que establece las bases para realizar análisis de confiabilidad e implementar las prioridades para establecer las estrategias para la inspección y el mantenimiento de todos los activos. En la tabla anterior se muestran la categorización por niveles de criticidad de los equipos en el área seleccionada, y en base a ellos se ajustaron datos de los equipos a la distribución de probabilidad Weibull detectándose que los equipos más conflictivos son la trituradora y el secador.
A continuación, se realizó el análisis de los indicadores de confiabilidad a partir del histórico de fallos de los equipos en los años 2014 y 2015 (figura 2), se determinaron los equipos con mayor frecuencia de fallas en el área, se calcularon los indicadores tiempo medio entre fallas (TMEF), tiempo promedio fuera de servicio (TPFS) y disponibilidad (tabla 2).
Figura 2
Frecuencia de fallas por equipos en el área de Materias Primas, durante los años 2014 y 2015

Tabla 2
Resumen de los Indicadores de confiabilidad calculados en el área de Materias Primas
Nombre |
Equipo |
Fallas |
TMEF |
TPFS |
Disponibilidad |
Transportador de placas |
221-TP1 |
129 |
194,9 |
3,35 |
60,30 |
Banda |
221-BT3 |
94 |
241,7 |
0,97 |
99,60 |
Banda |
291-BT3 |
71 |
217,2 |
1,41 |
99,35 |
Banda |
291-BT5 |
44 |
68,3 |
7,13 |
89,56 |
Banda |
291-BT6 |
43 |
50,2 |
1,23 |
97,56 |
Rascador de desecho |
221-RD1 |
33 |
601,0 |
0,76 |
99,87 |
Banda |
291-BT4 |
33 |
673,3 |
3,85 |
99,43 |
Trituradora |
211-AP2 |
31 |
561,5 |
4,02 |
99,28 |
Secador |
221-SE1 |
30 |
1 037,7 |
5,61 |
99,46 |
Criba |
221-CT1 |
28 |
96,0 |
3,26 |
96,60 |
Válvula de cambio |
291-DM2 |
27 |
43,1 |
0,57 |
98,68 |
Banda |
291-BT2 |
25 |
75,0 |
1,27 |
98,31 |
Totales |
|
840 |
|
|
|
Proceso: Materias Primas, Área: Materias Primas
Del análisis anterior se concluye que los equipos que presentan menor tiempo medio entre fallos son 291-DM2, 291-BT6, 291-BT5, 291-BT1, los que presentan mayor tiempo para reparar fallas son 291-BT5, 221-SE1, 211-AP2, 291-BT4 y los que presentan menor disponibilidad son 221-TP1, 291-BT5, 221-CT1.
De forma general, en el área de Materia Prima los equipos que presentaron problemas en cuanto a fallas y confiabilidad son: el Transportador de placas 221-TP1, las bandas transportadoras 221-BT3, 291-BT3, 291-BT5, 291-BT6, 291-BT4, 291-BT2, 291-BT1, 221-BT1, el rascador de desecho 221-RD1, la Trituradora 211-AP2, el Secador 221-SE1 y la Criba 221-CT1.
En la actualidad, en la empresa no se cuenta con un sistema de control operacional donde se establezca los tipos y frecuencia de revisiones por parte de los operadores de campo, así como de los parámetros fundamentales de la instalación que puedan identificar sucesos iniciadores de averías ni desviaciones del régimen tecnológico.
Prefijado el “fallo que se pretende evitar” en el sistema tecnológico, se fue descendiendo, escalón a escalón, a través de los sucesos inmediatos o sucesos intermedios hasta alcanzar los sucesos básicos que generan las situaciones que, relacionadas entre sí, contribuyen a la aparición del “fallo del subsistema”.
Se analizó la documentación técnica de la instalación, así como las instrucciones de operación y/o procedimientos de trabajo. De la documentación de la instalación fueron analizadas: diagramas del proceso e instrumentación (Flowsheets) con datos completos sobre los diversos componentes de la instalación (tuberías, válvulas, equipos, elementos de seguridad), sus características, sus condiciones de trabajo y sus limitaciones; así como las características y peligrosidad de las materias primas utilizadas, plano de emplazamiento de la instalación, características y disponibilidad de los servicios (CO2, aire, electricidad, combustibles) y descripción de los sistemas de seguridad.
Diseño inapropiado frente a: corrosión del medio y temperatura, fallos de elementos tales como motores, compresores, ventiladores, bandas, fallos de sistemas de control (censores de presión y temperaturas, analizadores de gases, controladores de nivel, reguladores de flujos y unidades de control computarizadas), fallos de sistemas específicos de seguridad (válvulas de seguridad, sistemas de alivio de presiones, sistemas de neutralización y avisadores) y fallos de juntas y conexiones.
Alteraciones incontroladas de los parámetros fundamentales del proceso (presión, temperatura, flujo, parámetros de las materias primas), fallos en los servicios (insuficiente enfriamiento, corte del suministro eléctrico, suministro de CO2, Aire comprimido, desempolvado), fallos en los procedimientos de parada o puesta en marcha, errores humanos y de organización, errores de operación, desconexión de sistemas de seguridad a causa de frecuentes falsas alarmas, errores de comunicación, incorrecta reparación o trabajo de mantenimiento, realización de trabajos no autorizados (soldadura, entrada en espacios confinados). Estos errores suelen suceder por no conocer suficientemente el peso de sus operaciones en el desempeño del sistema, insuficiente formación y adiestramiento en el trabajo y carga psíquica excesiva de los empleados.
En el análisis de fiabilidad de Materias Primas, el paso previo a la elaboración del árbol es la identificación del suceso no deseado y su probabilidad de ocurrencia. Esta etapa previa fue realizada por medio de un análisis histórico de accidentes en las instalaciones, aportando experiencias similares. El árbol queda conformado como ilustra la figura 3.
Figura 3
Arboles de fallas, instalación de Materias Primas.
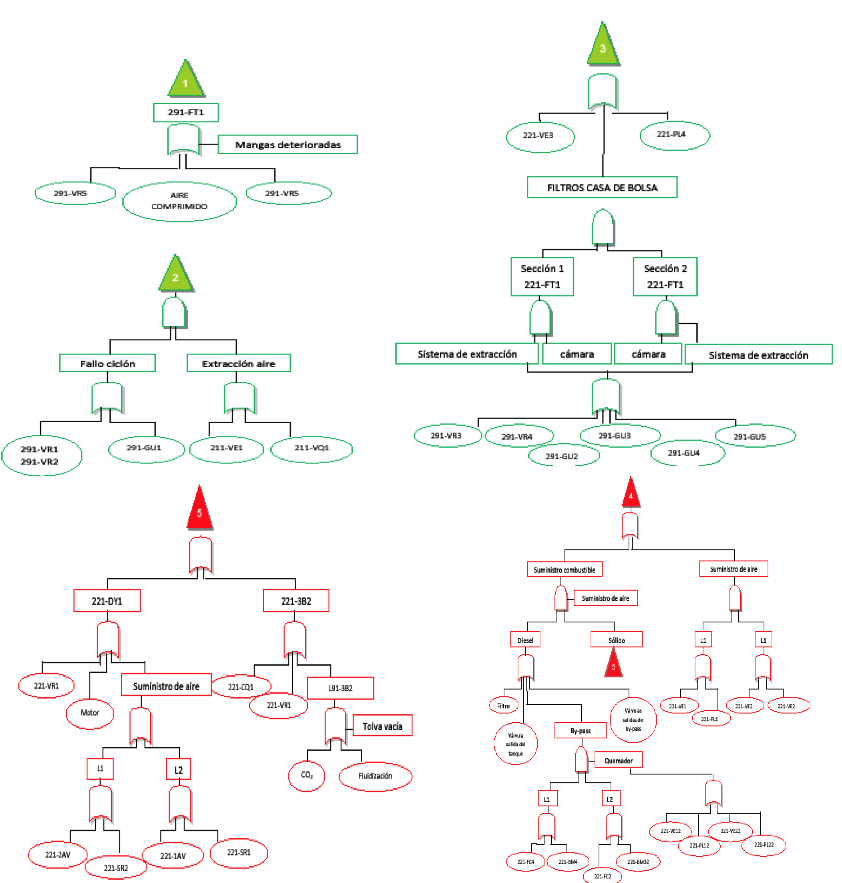
Elaboración de los autores.
La identificación de los equipos y modos de fallos que tienen un mayor impacto en la disponibilidad de la instalación de Materias Primas es lo que constituye un análisis de importancia del sistema. Este análisis permitió centrar la atención en aquellos equipos que han propiciado los sucesos básicos más importantes, a la vez que marcó las pautas a seguir para adoptar las medidas preventivas más eficaces que, obviamente, serán sobre aquellos equipos que muestren medidas de importancia más significativas. La importancia de los sucesos básicos fue calculada a través de diferentes medidas existentes, que realizan el análisis desde diferentes puntos de vista. En este documento se han considerado tres de las medidas más utilizadas.
Medida de importancia 1: proporciona la degradación del sistema en caso de ocurrir el suceso básico. La ordenación obtenida está basada en la disposición estructural de los sucesos básicos en el árbol de fallos, sin tener en cuenta explícitamente los valores reales de las indisponibilidades de los sucesos.
Medida de importancia 2: esta medida proporciona los sucesos básicos que más contribuyen al riesgo. Identifica aquellos sucesos básicos que si fueran perfectamente fiables, con indisponibilidad nula, conducirían a una reducción más importante en la indisponibilidad del sistema.
Medida de importancia 3: en esta medida influye tanto la indisponibilidad del componente como su posición estructural en el árbol de fallos.
En el caso práctico, los resultados obtenidos para las tres medidas de importancia muestran los siguientes resultados.
Medida 1: esta medida revela la importancia de asegurar las señales de control e indicaciones de parámetros locales, así como el suministro eléctrico, con revisiones horarias del personal de campo.
Medidas 2 y 3: estas medidas necesitan señales de control permanentes pero las revisiones pueden ser periódicas.
Finalmente, se confeccionó los árboles de fallos asociados a la instalación de Materias primas. Los resultados fueron utilizados en la confección de las listas de chequeo para el personal de operación de las instalaciones. Estas listas de chequeo contienen la frecuencia, los puntos, así como los parámetros operacionales identificadores de los sucesos iniciadores de eventos operacionales no favorables, que pueden ser utilizados en los análisis de mejoras. La implementación del procedimiento propuesto permitió a la cementera poseer un procedimiento para mejorar la disponibilidad técnica. En la aplicación realizada al proceso de materias primas se pudo apreciar mejoras en la disponibilidad técnica, traducidos a menor números de fallos y por tanto la elevación de la eficiencia del proceso.
El empleo de los árboles de fallos en los análisis operacionales de las instalaciones tecnológicas en la industria cementera constituye una herramienta para la identificación de eventos iniciadores de averías y equipamiento comprometido en su desarrollo para, de esta forma, confeccionar las listas de chequeo para las inspecciones durante la operación del personal del turno.
El empleo de las listas de chequeo facilita el trabajo del personal del turno por cuanto optimizan los tiempos de inspección del equipamiento, centrando la atención en aquellos puntos con mayor probabilidad de fallos que puedan indisponer la instalación.
Esta instalación, aunque tienen un alto nivel de automatización, requiere también la intervención humana, tanto en operaciones normales (vigilancia de procesos) como ocasionales, por alteraciones en las condiciones de trabajo que precisan de actuaciones correctas y rápidas para evitar su criticidad. Por ello, en este tipo de instalación para asegurar un comportamiento correcto y minimizar errores, exige la selección del personal adecuado y el perfecto conocimiento y adiestramiento sobre los procedimientos de trabajo tanto en circunstancias normales como en desviaciones de regímenes operacionales.
Contini, S., & Matuzas, V. (2012). Coupling decomposition and truncation for the analysis of complex fault trees. Journal of Risk and Reliability, 226(3), 249-261.
Dunnett, S., & Andrews, J. (2004). Analysis methods for fault trees that contain secondary failures. Journal of Process Mechanical Engineering, 218(2), 93-102.
Contini, S., & Matuzas, V. (2012). Coupling decomposition and truncation for the analysis of complex fault trees. Journal of Risk and Reliability, 226(3), 249-261.
Dunnett, S., & Andrews, J. (2004). Analysis methods for fault trees that contain secondary failures. Journal of Process Mechanical Engineering, 218(2), 93-102.
Hurdle, E., Bartlett, L. M., & Andrews, J. D. (2007). System fault diagnostics using fault tree analysis. Journal of Risk and Reliability, 221(1), 43-55.
Li, S., Si, S., Xing, L., & Sun, S. (2014). Integrated importance of multi-state fault tree based on multi-state multi-valued decision diagram. Journal of Risk and Reliability, 228(2), 200-208.
Majdara, & Wakabayashi. (2010). Automated fault tree construction for a sample chemical plant. Journal of Risk and Reliability, 224(3), 207-216.
Matuzas, V., & Contini, S. (2012). On the efficiency of functional decomposition in fault tree analysis. Proceedings of the Institution of Mechanical Engineers, 226(6), 635-645.
Nusbaumer, & Rauzy. (2013). Fault tree linking versus event tree linking approaches: a reasoned comparison. Journal of Risk and Reliability, 227(3), 315-326.
Pérez, C. M. (2012). Procedimiento para la mejora de la confiabilidad operacional. Caso de estudio: Cementos Cienfuegos S.A. Tesis de maestría en Ingeniería Industrial, Universidad de Cienfuegos.
Shneiderman, Dunne, C., Sharma, P., & Wang, P. (2012). Innovation trajectories for information visualizations: Comparing treemaps, cone trees, and hyperbolic trees. Information Visualization, 11(2), 87-105.
Zheng Liu, Yan-Feng, Li-Ping He, & Hong-Zhong Huang. (2014). Proceedings of the Institution of Mechanical Engineers. Journal of Risk and Reliability, 228(4), 371-381.
1. , Universidad Metropolitana del Ecuador, carrera de Ciencias Administrativas y Contables CPA. Master en Administración de Negocios. Correo electrónico de contacto: glopezc@umet.edu.ec
2. Universidad de Guayaquil, Master en Desarrollo Socio Económico Local. Correo electrónico de contacto: iran.alonsoh@ug.edu.ec
3. Universidad de Guayaquil, PHD. en Economía. Correo electrónico de contacto: zahily.mazairar@ug.edu.ec
4. Docente del Departamento de Ingenieria Industrial, Universidad de Cienfuegos. Doctor en Ciencias Técnicas. Correo electrónico de contacto: hricardo@ucf.edu.cu