
 HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN
HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN Espacios. Vol. 37 (Nº 34) Año 2016. Pág. 16
André Mauro Santos de ESPÍNDOLA; Maria Emilia CAMARGO 1; Ana Cristina FACHINELLI
Recibido: 21/06/16 • Aprobado: 30/07/2016
5. Análise e discussão dos resultados
6. Considerações finais e recomendações
RESUMO: Este estudo teve como objetivo identificar qual o modelo de previsão de consumo para análise das informações no processo de Inteligência Competitiva em uma empresa do setor metalúrgico localizada no estado do Rio Grande do Sul. No desenvolvimento do estudo foram utilizados os temas Big Data, Data Mining, Previsão de Demanda e Inteligência Competitiva com a finalidade de responder à seguinte questão: Qual o modelo de previsão de consumo de aço que pode ser usado para análise das informações no processo de Inteligência Competitiva? Na realização do estudo foram analisados dados internos e externos a empresa na busca pela identificação de correlação entre o consumo de aço da empresa e variáveis econômicas que posteriormente foram utilizadas na identificação do modelo de previsão de consumo. Foram identificados dois modelos, um univariado sem intervenção através da metodologia de Box e Jenkins, o segundo modelo foi um modelo de previsão com Função de Transferência. Os dois modelos apresentaram uma boa capacidade de descrever a série histórica do consumo de aço, mas o modelo univariado apresentou melhores resultados na capacidade de previsão. |
ABSTRACT: This study aimed to identify the consumption forecasting model to analyze the information in the competitive intelligence process in a company in the metallurgical sector in the state of Rio Grande do Sul. In preparing the study subjects were used Big Data, Data Mining Forecasting Demand and Competitive Intelligence in order to answer the question: What is the steel consumption forecast model that can be used to analyze the information in the competitive intelligence process? In the study were analyzed internal and external data the company in the search for identifying correlation between steel consumption of the company and economic variables that were later used in the identification of consumption forecast model. Two models were identified, one univariate without intervention by Box and Jenkins methodology, the second model was a forecasting model with transfer function. Both models showed a good ability to describe the historical series of steel consumption, but the univariate model showed better results in predictive power. |
O processo de globalização tem modificado as inter-relações dinâmicas entre assuntos internacionais, nacionais, regionais e locais, de um lado; e de outro, todos os campos do interesse humano, incluindo a economia, a ciência, a tecnologia, a política, a religião, a cultura, as comunicações, o transporte, a educação, a saúde e a ecologia (HARRIS, 2002). Na economia a grande modificação está na relação entre as empresas de grande, médio e pequeno porte com o mercado que está cada vez mais exigente e competitivo.
Outro fator que tem modificado as inter-relações é o desenvolvimento da tecnologia da informação, desenvolvimento este que faz com que Drucker (1993) defina sociedade atual como “sociedade do conhecimento” onde a diferença com relação às sociedades do passado está diretamente relacionado com a importância do conhecimento. Para Drucker (1993), a importância do conhecimento é latente quando ele assume o papel do recurso mais significativo atualmente.
Stewart (1998, p. 8), afirma que a informação e o conhecimento são as principais armas competitivas desta época. O autor complementa dizendo “o conhecimento é mais valioso e poderoso do que os recursos naturais, grandes indústrias ou polpudas contas bancárias”. Para Stewart (1998) a força do conhecimento atinge todos os setores e as empresas que têm os melhores resultados são as que têm as melhores informações ou as que têm o melhor controle das informações.
Na busca pela vantagem competitiva em um ambiente onde as bases da competição como posição geográfica e regulamentação de mercados não estão mais disponíveis, a competição passa pela tomada de decisões inteligentes e rápidas com base nas análises das informações pelos líderes das empresas (DAVENPORT, 2007).
Neste contexto surgem questões fundamentais para a utilização da informação no processo decisório pelos líderes das empresas:
Para responder estas questões este estudo buscou combinar o fenômeno Big Data, Data Mining e modelos de previsão como uma ferramenta de Inteligência Competitiva. Dessa combinação surgiu o modelo teórico apresentado na Figura 1, onde o Big Data é a fonte de dados, o Data Mining é responsável pela identificação e coleta e os modelos de previsão são instrumentos de análise em um processo de Inteligência Competitiva.
Figura 1 – Representação gráfica do modelo teórico
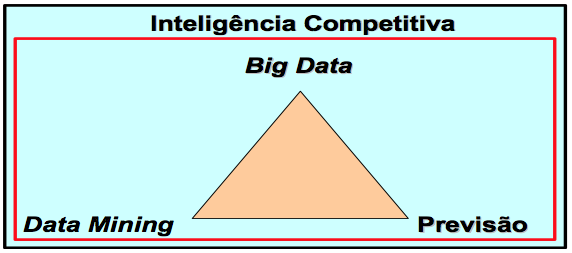
Fonte: Elaborado pelo pesquisador
O objeto de estudo foi a empresa Metalúrgica Alfa Ltda, com matriz no estado do Rio Grande do Sul. Atualmente emprega cerca de 1.300 funcionários em suas quatro unidades fabris no Rio Grande do Sul, uma unidade produtiva no Estado de Pernambuco, uma unidade produtiva no Estado de Goiás e um centro de distribuição na América Central.
Os autores citados trazem a importância da informação e do conhecimento nos dias atuais como uma forma de se obter vantagem competitiva. Nesta conjuntura a busca por dados, a transformação destes em informação e o uso desta informação como conhecimento através da inteligência competitiva passa a ter um papel fundamental no planejamento estratégico das empresas.
Neste contexto as empresas precisam saber onde obter dados, como extrair informação destes dados, como transformar esta informação em conhecimento e como utilizar este conhecimento de forma inteligente no do processo de tomada de decisões.
No sentido de contribuir com elementos de respostas para estas questões, este estudo apresenta aspectos teóricos e práticos utilizados para identificação de um modelo de previsão de consumo de aço. Para tanto a pesquisa apresenta uma possível fonte de dados, os processos de extração de informação desses dados e um modelo capaz de transformar essa informação em conhecimento.
O mundo vive um contínuo e acelerado processo de transformação que envolve todas as áreas do conhecimento. É possível afirmar que a velocidade desse processo tem uma relação direta com a rapidez em que ocorrem as mudanças na área tecnológica. Estas mudanças têm tornado cada vez mais as relações globalizadas, modificado as transações comercias e fazendo com que as empresas repensem as formas de competir.
Davenport (1998), com base em opiniões de autoridades e de equipes de venda de empresas de informática, afirma que estamos em uma nova era da informação, que irá revolucionar a maneira como se trabalha, compete e até mesmo como se pensa no mercado.
Fachinelli et al. (2007, p. 162) corroboram com a visão do autor ao afirmar que “o grande desenvolvimento das novas tecnologias de informação provocou profundas modificações no comportamento da sociedade contemporânea, criou novas formas de ação e interação e assim transformou a organização espacial e temporal da vida social”.
Atualmente existem diversas denominações para a sociedade em que vivemos, por exemplo, para Drucker (1993), vivemos na sociedade do conhecimento que se diferencia das épocas passadas pela importância do conhecimento. Segundo Drucker (1993), é claro que o conhecimento assume um papel diferenciado entre os recursos, mas ele não é mais um recurso como trabalho, capital e terra, mas sim um recurso único, o mais significativo e singular nesta sociedade.
Tarapanof (2001), denomina a sociedade como sociedade de informação, para ela a nossa sociedade é resultado desses novos referenciais sociais, econômicos, tecnológicos e culturais, os quais também provocam um conjunto significativo de mudanças de enfoque no âmbito das sociedades e de suas organizações. Nesta conjuntura, Tarapanof (2001) destaca o papel da informação, afirma que ela é a principal matéria-prima da sociedade e que esta pode ser tratada até como “um insumo comparável à energia que alimenta os sistemas”.
Para Nonaka e Takeuchi (2002), a informação traz a possibilidade de se observar a interpretação de eventos ou situações de forma diferente. Eles consideram a informação como um meio de onde se extrair o conhecimento.
Fachinelli et al. (2007) asseguram que a obtenção de bons resultados passa pela necessidade das empresas revisarem seus conceitos e pela busca de caminhos que permitam a utilização de toda a informação que se encontra espalhada.
Fachinelli et al. (2007, p. 173) não citam a informação como o elemento de diferenciação de produto, mas trazem a informação como um elemento chave para boas estratégias, dizendo que a “informação permite que a empresa tenha subsídios para uma decisão rápida e consistente”.
O desenvolvimento da tecnologia da informação através de novos equipamentos, sistemas, segurança e Internet tem influenciado significativamente no crescimento do armazenamento e no fluxo de informações. Este tem sido um fator com influência destacada nas mudanças da sociedade e nas organizações através do mundo. Uma das mudanças mais significativas está relacionada com o armazenamento e com a divulgação de dados pessoais ou de organizações governamentais e não governamentais através da Internet e outras fontes eletrônicas.
O Big Data é um sistema onde os participantes, de maneira consciente ou inconsciente, ofertam dados contínuos sobre si mesmos que, pelo “efeito rede” são coletados constantemente e organizados através de rápidas taxas logarítmicas (MCKINSEY, 2011).
Segundo o EMC (2011), o termo Big Data não é um termo exato, ele se caracteriza por um processo interminável de acúmulo de todos os tipos de dados, onde alguns destes dados são estruturados, mas a maior parte são dados desestruturados. Esse conjunto de informações não é composto somente por transações de dados, nele encontram-se vídeos, fotos, conversas, índices de pesquisas, resultados de exames médicos, estas informações são produzidas a cada instante por pessoas através de relações comerciais ou pessoais.
O sistema de organização e captura dos dados, armazenados na rede de forma virtual através de nuvem e as inovações em software e ferramentas para análise por meio de atividades dinâmicas em tempo real também fazem parte do Big Data (IDC, 2011).
O Data Mining ou Mineração de Dados é parte de um processo mais amplo denominado busca do conhecimento em banco de dados. Com o desenvolvimento da tecnologia da informação, o armazenamento de informações em banco de dados tem crescido de forma exponencial. Este processo vem se desenvolvendo há algumas décadas, mas tem obtido mais destaque após o fenômeno Big Data. As empresas e as instituições governamentais ou não governamentais têm a necessidade cada vez maior de organizar e armazenar as informações em banco de dados.
Braga (2005, p. 11) define a mineração de dados como “uma coleção de técnicas e métodos facilitadora da aquisição e retenção da parte do mercado que cabe a uma empresa”, ou seja, o autor apresenta a mineração não como uma técnica específica, mas como um conjunto de técnicas e direciona sua aplicação como parte de uma estratégia de obtenção de espaço no mercado. A busca pela informação não tem origem somente no uso de ferramentas genéricas, mas também na capacidade dos analistas identificarem padrões e preverem os resultados com base em dados estratégicos de uma organização (BRAGA, 2005).
As séries temporais são conjuntos de observações de uma determinada variável ordenada conforme uma unidade de tempo (CAMARGO; SOUZA, 1996), para Souza (1989), uma série temporal é a classe de fenômenos cujo processo observacional e consequente quantificação numérica gera uma sequência de dados distribuídos no tempo.
Pelas definições fica evidente que uma série temporal é uma sequência de valores que uma determinada grandeza assume em intervalos de tempo. A variável independente em uma série temporal é o tempo, e dependendo da unidade de tempo adotada, a série pode ser classificada em discretas e contínuas.
Os modelos univariados de Box e Jenkins são uma metodologia bastante utilizada para construção de modelos paramétricos (MORETTIN; TOLOI, 2006) e são capazes de manipular séries temporais de qualquer natureza além de ter como objetivo a construção de um modelo Autorregressivo Integrado de Médias Móveis (ARIMA).
A metodologia desenvolvida por Box e Jenkins se caracteriza por interpretar uma série temporal como resultado de um vetor aleatório multivariado com dimensão definida pela série (CAMARGO; SOUZA, 1996). O objetivo da metodologia é buscar e detectar o sistema gerador da série através de informações da própria série (CAMARGO; SOUZA, 1996).
Um modelo é classificado como univariado por representar somente o estudo de uma única série temporal. Este tipo de modelo é denominado de sem intervenção quando não existe impacto de um elemento externo no comportamento de uma determinada série temporal. A intervenção pode ser caracterizada por modificações de legislação, crises políticas, crises econômicas, modificações do clima, etc.
Os modelos univariados sem intervenção podem ser: Modelo Geral; Modelo ARIMA(p,d,q); Modelo Autorregressivo de ordem p – AR(p); Modelo de Média Móvel de ordem q – MA(q); Modelos Mistos Autorregressivos e de Médias Móveis – ARMA(p,q)
Os modelos apresentados anteriormente são modelos univariados, ou seja, modelos de previsão que descrevem o comportamento de uma série temporal com base somente em seu passado. Os modelos de função de transferência têm como objetivo descrever o comportamento de uma série com base no seu comportamento passado e no comportamento de outras séries temporais que podem explicar o comportamento da série estudada.
Neste tipo de modelo a série temporal Yt é causada de forma casual unidirecional pelas variáveis X1,t, X2,t, ..., Xk,t.
A análise de séries temporais multivariadas é um método que busca descrever as relações entre diversas séries temporais (BOX, JENKINS, REINSEL, 2008). A metodologia adotada consiste em considerar as séries estudadas com componentes de um vetor de séries temporais. O estudo deste vetor busca descrever o estudo das relações existentes entre os componentes dele (BOX, JENKINS, REINSEL, 2008). Este procedimento é necessário quando as séries estudadas têm um relacionamento simultâneo ao longo de um período de tempo.
Para o estudo de processos multivariados, um quadro é necessário a fim de descrever não apenas as propriedades da série individual mas também as possíveis relações transversais entre as séries e as relações possíveis entre transversais da série (BOX, JENKINS, REINSEL, 2008). A compreensão das relações existentes entre as séries se dá através do estudo da estrutura das correlações entre os componentes da série com o objetivo de determinar um modelo que represente estas relações ao longo do tempo para assim melhorar a precisão das previsões das séries individuais (BOX, JENKINS, REINSEL, 2008).
O presente estudo buscou identificar modelos de previsão de consumo de aço para análise das informações no processo de Inteligência Competitiva. Na busca pelos modelos foi realizada a observação e a manipulação de variáveis internas e externas à empresa, para Gil (2002) estas são características de um estudo científico. O estudo foi de natureza aplicada, já que teve razão de ordem prática a qual buscou “conhecer com vistas a fazer algo de maneira mais eficiente ou eficaz” (GIL, 2002, p. 17) neste caso, conhecer melhor a consumo de aço da empresa para a análise das informações no processo de Inteligência Competitiva.
No desenvolvimento do estudo duas abordagens foram adotadas, a primeira buscou analisar fontes internas e externas na busca de dados primários e secundários para definir o problema com mais precisão, identificando e classificando as principais variáveis a serem estudas na fase quantitativa. Estas características para Malhotra (2010), definem a abordagem como sendo qualitativa. O autor também afirma que “a pesquisa qualitativa proporciona melhor visão e compreensão do problema. Ela investiga o problema com algumas noções preconcebidas sobre os resultados dessa investigação” (MALHOTRA, 2010, p. 122). “A pesquisa qualitativa exploratória é útil quando o pesquisador não conhece as variáveis importantes a examinar” (CRESWELL, 2007, p. 38). Esta foi a situação encontrada neste estudo, pois se buscou a identificação das variáveis externas que têm impacto no consumo de aço da Empresa Alfa para posterior construção de um modelo de previsão de consumo através de modelos de Box e Jenkins com função de transferência.
A segunda abordagem buscou avaliar as variáveis para verificar evidências de correlação e construir modelos de previsão de consumo de aço através de modelos Box e Jenkins com função de transferência, características que Malhotra (2010) atribui a uma pesquisa quantitativa. Creswell (2007, p. 38) contribui para esta classificação quando afirma que “se o problema é identificar os fatores que influenciam um resultado, a utilidade de uma intervenção ou a compreensão dos melhores previsores de resultados, então é melhor usar uma técnica quantitativa”.
Este estudo foi operacionalizado através de um estudo de caso. As fontes de informações serão a Empresa Metalúrgica Alfa e os dados existentes no Fenômeno Big Data, para a exploração das fontes de dados foi utilizado o processo de Data Mining.
O Data Mining, mineração em bases de dados da empresa teve como finalidade mapear dados do mercado com influência no consumo de aço para uma posterior prospecção de índices e indicadores financeiros no site do Banco Central do Brasil (BACEN) (2012).
O estudo da previsão de consumo da empresa Alfa foi limitado ao período de janeiro de 2007 a maio de 2012.
A pesquisa qualitativa foi exploratória e desenvolvida através de procedimento de mineração de dados. O objetivo foi o de identificar os setores da economia em que as variáveis ou indicadores de mercado tinham alguma relação com a consumo de aço da Alfa.
A identificação das variáveis seguiu duas frentes, a primeira foi a de uma análise do mercado do aço no Brasil, buscando identificar os setores da economia com relação direta com este mercado. A segunda frente teve desenvolvimento na análise da base de dados dos clientes da Alfa, buscou-se então conhecer os setores da economia do qual fazem parte através da classificação dos mesmos pela Classificação Nacional de Atividades Econômicas (CNAE). A coleta de dados para realização da identificação das variáveis foi feita a através da mineração de dados nos sites do Ministério de Minas e Energia e no Instituto Aço Brasil.
A pesquisa quantitativa foi dividida em duas etapas:
Primeira etapa: foi feita uma análise de correlação entre as variáveis econômicas, pesquisadas na fase qualitativa e a consumo de aço da Alfa no período compreendido entre janeiro de 2007 e maio de 2012.
Segunda etapa: teve como objetivo a identificação dos modelos de previsão de consumo de aço relacionando o consumo com as variáveis econômicas identificadas na etapa anterior. Para construção dos modelos foi utilizada a metodologia univariada e de função de transferência de Box e Jenkins.
A aquisição de dados para a etapa quantitativa foi guiada pelos resultados obtidos na etapa qualitativa de identificação dos setores econômicos relacionados com o consumo de aço. Com os resultados obtidos foi feita uma mineração de dados no Sistema Gerenciador de Séries Temporais (SGS), do Banco Central, em busca de variáveis econômicas relacionadas com os setores da economia pesquisados anteriormente.
Para Yin (2010), a definição do caso de estudo, unidade de análise, é um dos componentes importantes de um projeto de pesquisa que envolva o estudo de caso. Neste trabalho o caso de estudo foi à empresa Metalúrgica Alfa Ltda., com matriz em Bento Gonçalves, no Rio Grande do Sul.
O trabalho teve foco na unidade de sistemas de armazenagem e soluções em logística e armazenagem de produtos. Ele teve como objetivo identificar os modelos mais adequados para a previsão de consumo de aço considerando o impacto de variáveis externas com influência no comportamento do mercado. A escolha desta empresa se justifica pela sua importância econômica para região e comunidade a qual ela pertence; importância do setor metalúrgico para a economia local e nacional e disponibilidade de dados estratégicos da empresa para realização do estudo.
A coleta de dados para o desenvolvimento deste estudo seguiu três frentes: Coleta de informações sobre o mercado do aço no Brasil; Coleta de informações na empresa Alfa; Coleta de informações junto ao Sistema gerenciador de séries temporais do BACEN (2012);
A coleta de dados sobre o mercado do aço no Brasil teve com objetivo reconhecer as principais características deste mercado para posterior identificação dos setores da economia que podem influenciar o consumo de aço da empresa Alfa.
A coleta de informações sobre a empresa Alfa teve como finalidade a construção de dois bancos de dados. O primeiro teve a finalidade de identificação e classificação dos clientes da empresa com o propósito de identificar os setores da economia aos quais eles pertencem, o segundo banco teve como finalidade a análise de correlação e a identificação do modelo de previsão de consumo de aço da empresa Alfa.
Na etapa qualitativa da pesquisa foi feito um levantamento de informações necessárias para identificação dos setores econômicos e os seus respectivos indicadores que tinham alguma relação com o consumo de aço da empresa Alfa.
Para estudar o consumo de aço da Empresa Alfa e identificar no mercado variáveis ou indicadores financeiros que possam ter influência sobre esta, foi feito um levantamento das características do mercado do aço brasileiro. Os dados obtidos são referentes à consolidação do mercado até o ano de 2011 e à situação da produção de aço até maio de 2012. As informações foram obtidas junto ao Instituto Aço Brasil (IABR) e ao Ministério de Minas e Energia (MME).
Com o objetivo de construir uma base de dados sobre os clientes da empresa Alfa e sobre o consumo de aço foi solicitado à empresa o acesso às seguintes informações: tipo de Aço utilizado pela empresa Alfa; consumo mensal de Aço; pedidos com nomes de clientes; solicitação de orçamento com a situação após o orçamento; relação de Operadores Logísticos; relação de Clientes por faturamento e valor pago pelo aço em cada compra.
Após o recebimento das informações da empresa, iniciou-se o processo de avaliação, formatação e construção dos bancos de dados para a pesquisa.
O primeiro banco de dados teve como finalidade análise e identificação dos possíveis fatores externos que podem influenciar o consumo de aço da empresa Alfa através da classificação dos clientes conforme tabela de Classificação Nacional de Atividade Econômica (CNAE). O segundo banco de dados teve como objetivo a análise de correlação entre o consumo de aço e as variáveis externas.
O banco de dados com a relação dos clientes era composto por 10.557 negociações no período de janeiro de 2007 a maio de 2012. Para realizar a análise do banco de dados foi feita uma amostragem probabilística aleatória simples de uma população finita (PEREIRA, 1979), considerando-se um erro de 5% e uma confiança de 95%, com isto foi obtida uma amostra com 360 clientes.
Com a amostra definida foi realizada uma classificação dos clientes conforme a atividade econômica baseada na tabela CNAE (IBGE, 2012). A classificação foi realizada através de uma consulta do Cadastro Nacional de Pessoa Jurídica (CNPJ) no site da Receita Federal para identificar o código e descrição da atividade econômica principal. O código obtido na Receita Federal foi utilizado para identificar os setores da economia e as atividades econômicas dos clientes da empresa Alfa.
A etapa quantitativa da pesquisa teve por finalidade avaliar a relação entre às variáveis do mercado através de uma análise de correlação e identificar o modelo de previsão de consumo de aço da empresa Alfa através da metodologia de Box e Jenkins com função de transferência. Esta etapa ficou dividida em: análise de correlação; ciclo de Box e Jenkins para construção do modelo Univariado; construção do Modelo com Função de Transferência e análise dos resultados obtidos.
Para identificar a relação entre as variáveis de mercado obtidas através da mineração de dados no SGS, do Banco Central, e o consumo de aço da empresa Alfa, foi realizada uma análise de correlação. Esta tem como propósito saber como se comporta uma variável conhecendo o comportamento de outras variáveis relacionadas (SAMPIERI; COLLADO; LUCIO, 2001, p. 63).
Em um primeiro momento realizou-se uma análise de correlação com todas às variáveis envolvidas e a variável consumo de aço da empresa Alfa, não se considerando os supostos paramétricos, pois o objetivo era identificar o tipo de correlação existente para diminuir o número de variáveis. O critério utilizado foi a classificação da força de uma correção apresentada por Santos (2007), as variáveis com correlação no intervalo de -0,6 e 0,6 foram retiradas do estudo.
Após a primeira análise e a retirada do estudo dos indicadores econômicos, com coeficiente de correlação fora dos do intervalo estipulado foram verificados os supostos paramétricos, estes são requisitos que devem ser respeitados para que os testes paramétricos possam ser aplicados, caso os supostos não sejam respeitados, os testes aplicados devem ser não paramétricos (HAIR JR. et al., 2005), os supostos paramétricos verificados foram: a variável dependente é quantitativa contínua, medida pelo menos em uma escala de intervalo; a amostra é maior que trinta elementos; a população é normalmente distribuída; há homoscedasticidade entre os grupos de variáveis.
Ao avaliar o conjunto de dados foi possível verificar que os dois primeiros supostos eram respeitados pelo conjunto, pois as variáveis estudadas eram contínuas e o tamanho da amostra é era que 30.
Para verificar a normalidade dos dados foi aplicado o teste de Kolmogorov-Smirnov (HAIR JR. et al., 2005 p. 78) já a homoscedasticidade foi avaliada pelo teste Levene (HAIR JR. et al., 2005, p.79). Este indicou que esta condição não era respeitada, essa etapa do estudo fica restrita a uma análise de correlação e, para este, o resultado do teste de Levene (HAIR JR. et al., 2005, p.79) não terá influência, mas na identificação dos modelos de previsão este resultado foi levado em consideração. O teste Kolmogorov-Smirnov foi possível verificar que a significância foi maior que 0,05 para todas as variáveis o que nos impede de rejeitar a hipótese de os dados seguem uma distribuição normal.
Tendo realizado a avaliação dos supostos paramétricos foi possível realizar a análise de correlação entre as variáveis externas e o consumo de aço da empresa Alfa.
Todas as variáveis apresentaram um coeficiente de correlação superior a 0,6, o que para Santos (2007) representa uma correlação moderada positiva.
Segundo Camargo e Souza (1996) e Fischer (1982) as hipóteses básicas para encontrar modelo de previsão são o conjunto de dados seguir uma distribuição normal e a variância desse conjunto ser constante, ou seja, existe homocedasticidade. Se as condições não forem respeitadas, a série estudada deve passar por um processo de transformação que tem como objetivo estabilizar a variância e fazer com que o conjunto de dados seja supostamente normal.
A homocedasticidade foi avaliada pelo teste Levene (HAIR JR. et al., 2005, p.79). Neste teste se verifica se existe uma diferença significativa entre as variâncias, para tanto a hipótese nula afirma que não existe diferença entre as variâncias contra a hipótese alternativa a qual afirma existir diferença entre as variâncias. A hipótese nula deve ser rejeitada, ou seja, existe uma diferença significativa entre as variâncias. Esta pode indicar a necessidade de algum tipo de transformação das variáveis, condição que será avaliada novamente durante o processo de identificação do modelo.
Além dos pressupostos de normalidade e homocedasticidade foi preciso avaliar a multicolinearidade. Uma multicolinearidade elevada pode prejudicar a capacidade de prever efeitos sobre a variável, o fator de inflação de variância (VIF) é utilizado para avaliar a multicolinearidade, o VIF não pode exceder o valor de 10. Na primeira análise de multicolinearidade muitas das variáveis estudadas apresentaram um VIF muito superior a 10, para resolver este problema retiramos do conjunto de variáveis as que apresentaram valores elevados de VIF.
Segundo Morettin e Toloi (1987), a construção dos modelos de Box e Jenkins é um ciclo composto pelas seguintes etapas: identificação de uma classe geral de modelos que será analisada; especificação do modelo, base na análise de autocorrelações, autocorrelações parciais e outros critérios; estimação dos parâmetros do modelo; verificação do modelo ajustado, através da análise dos resíduos para medir a adequação do modelo para realização de previsões; reiniciar o ciclo se o modelo não for adequado.
O primeiro passo no processo de identificação do modelo foi a análise do gráfico da série de consumo de aço da empresa Alfa. Essa análise teve como finalidade a identificação informal da presença de tendência, sazonalidade ou alterações na variância. Tais informações podem indicar se a série é ou não estacionária e se a mesma necessita ou não de uma transformação prévia.
Em uma análise informal das características do consumo de aço da empresa Alfa, foi possível verificar que a série estudada parece ser estacionária com um conjunto de picos, eles parecem se repetir periodicamente o que sugere uma possível sazonalidade. A confirmação ou não dessas características foi feita posteriormente através das análises da função de autocorrelação (ACF) e função de autocorrelações parciais (PACF) além do teste da raiz unitária.
Também foi feita uma análise do Histograma de distribuição de frequências da variável consumo. O conjunto de dados se aproxima de uma distribuição normal, condição esta verificada anteriormente no teste de Kolmogorov-Smirnov, mas, apresenta uma certa assimetria o que pode indicar a necessidade de algum processo de transformação da variável para construção do modelo. Com o objetivo de confirmar esta análise, foram calculadas as estatísticas descritivas da variável consumo de aço.
Os valores da curtose e da assimetria confirmam um certo grau de assimetria moderada e certo grau de curtose o que indica alguma variabilidade. Segundo Morettin e Toloi (2006), os problemas de simetria podem ser resolvidos através de uma transformação da variável, que torna o conjunto de dados mais simétrico e próximo da distribuição da normal.
O comportamento da FAC e da PACF observado em seus respectivos gráficos indicaram que a função consumo decresce rapidamente para zero, o que mais uma vez indica a estacionaridade da série. A confirmação estatística da estacionaridade da série foi verificada através da aplicação do teste aumentado de Dickey Fuller (ADF) para verificar a presença de raiz unitária.
O teste foi realizado no software Gretl versão 1.9.12 e os resultados avaliados conforme valores críticos tabelados por Fuller e citado por Gujarati (1995, p. 815).
Conforme os resultados do teste ADF, com constante e com constante e tendência a série de consumo de aço é uma série estacionária a um nível de 1%, ou seja, a série respeita a condição de estacionaridade necessária para identificação de um modelo pela metodologia de Box e Jenkins Box. A interpretação do teste também indica que a série deve ser considerada não estacionária se avaliada sem constante.
Analisando os comportamentos das FAC e PACF através de seus respectivos gráficos e comparando os resultados obtidos com o , onde n representa o número de observações, foi possível verificar que somente as duas primeiras autocorrelações são superiores a e sendo assim são significativamente diferentes de zero, levando à suposição de que deve haver processo AR(2). Além disso, o comportamento da FAC aparenta uma mistura de exponencial com ondas senoidais amortecidas característica, que para Morettin e Toloi (2006, p. 153) confirmam o processo AR(2).
Os comportamentos da FAC e da PACF apresentaram a possibilidade de existência de uma componente de sazonalidade. No FAC os lags 12 e 24 são significativamente diferentes de zero e no PACF o comportamento se repete no lag 12. Este comportamento pode evidenciar um processo SARIMA ou um processo MA(q) com defasagem 12.
Com base nestas interpretações foi possível estabelecer algumas hipóteses de modelos apresentadas na Tabela 1.
Tabela 1 – Hipóteses de Modelos para variável consumo de aço.
Nº |
Modelos |
1 |
ARIMA (2, 0, 0) |
2 |
ARIMA (2, 0, 1) |
3 |
ARIMA (2, 0, 2) |
4 |
SARIMA (2, 0, 0) (1, 0, 1) |
5 |
SARIMA (2, 0, 0) (1, 0, 2) |
6 |
SARIMA (2, 0, 0) (2, 0, 1) |
7 |
SARIMA (2, 0, 0) (2, 0, 2) |
8 |
Modelo Automático gerado pelo pacote computacional. |
Fonte: Elaborado pelo pesquisador
Foi possível descartar os modelos 3, 5, 6 e 7 por estes apresentarem parâmetros que não eram estatisticamente significativos ao nível de significância de 5% (z = 1,96). A avaliação dos modelos 1, 2, 4 e 8 levou em consideração os critérios de Akaike, Schwarz e Hannan-Quinn. Nestes os modelos 2 e 8 apresentaram os menores valores, o que indicou que os dois eram mais parcimoniosos. Importante destacar que o modelo número 2 foi o primeiro modelo identificado através da análise das FAC e PACF, e que o modelo 8 foi o modelo gerado automaticamente pelo sistema, considerando a série de dados como não estacionária sem constante, classificação esta que foi verificada quando da análise do teste ADF.
Na busca de identificação do melhor modelo, decidiu-se não escolher um modelo único nesta etapa do trabalho. Trabalhou-se com os modelos 2 e 8 nas etapas posteriores para verificar qual dos dois apresentariam melhores resultados. Na Tabela 3, apresenta-se os parâmetros e as estatísticas dos supostos modelos para a série consumo do aço, dados estes obtidos através do software Gretl.
Tabela 2 – Modelos estimados e suas estatísticas para variável consumo de aço.
Modelo 2: ARIMA (2, 0, 1) usando as observações 2007:01-2012:05 |
|||||||||
Parâmetros |
Coeficiente |
Erro Padrão |
Z |
p-valor |
|||||
Const |
1,48749e+06 |
152055 |
9.7826 |
<0.00001 *** |
|||||
Phi_1 |
0,330736 |
0.118094 |
2.8006 |
0.00510 *** |
|||||
Phi_2 |
0,304647 |
0,116892 |
2,6062 |
0,00915 *** |
|||||
Theta_12 |
0,327288 |
0,111904 |
2,9247 |
0,00345 *** |
|||||
Estatísticas do Modelo |
|||||||||
Média var. dependente |
1492617 |
|
D.P. var. dependente |
466028.2 |
|||||
Média de inovações |
22038,59 |
D.P. das inovações |
364324,3 |
||||||
Log da verossimilhança |
-925,5225 |
Critério de Akaike |
1861,045 |
||||||
Critério de Schwarz |
1871,917 |
Critério Hannan-Quinn |
1865,335 |
||||||
Modelo 8: SARIMA (0, 1, 1) (1, 0, 0) usando as observações 2007:01-2012:05 Observação: Modelo automático gerado pelo pacote computacional |
|||||||||
Parâmetros |
Coeficiente |
Erro Padrão |
Z |
p-valor |
|||||
Phi_1 |
0,354598 |
0,125742 |
2,8200 |
0,00480 |
*** |
||||
Theta_1 |
-0,646614 |
0,0843768 |
-7,6634 |
<0,00001 |
*** |
||||
Estatísticas do Modelo |
|||||||||
Média var. dependente |
15825,72 |
|
D.P. var. dependente |
473399,0 |
|||||
Média de inovações |
29758,70 |
D.P. das inovações |
371214,2 |
||||||
Log da verossimilhança |
-912,6574 |
Critério de Akaike |
1831,315 |
||||||
Critério de Schwarz |
1837,791 |
Critério Hannan-Quinn |
1833,866 |
||||||
Fonte: Elaborado pelo pesquisador
Nesta etapa foi feita a verificação dos modelos identificados na etapa anterior, para isto foram feitas as análises gráficas da FAC e PACF dos resíduos dos dois modelos, a aplicação do teste de Portmanteau e avaliação dos resultados através das estatísticas dos dois modelos.
Através da análise dos gráficos foi possível verificar que a FAC e PACF dos resíduos do modelo 2 permanecem dentro dos limites de confiança. Avaliando o conjunto de correlações pelo teste de Portmanteau, a estatística Q apresentou um valor de 14,95551, a um nível de significância de 5%, o valor tabelado do Qui-quadrado, para 21 graus de liberdade é de 32,67056, o que confirma a hipótese nula que os resíduos são brancos.
A análise da A FAC e PACF dos resíduos do modelo 8 mostrou que este modelo apresentou que alguns valores pareciam estar fora dos limites de confiança, mas avaliando os p valores individualmente foi possível verificar que todos eram significantes. O teste de Portmanteau para avaliar o conjunto de correlações apresentou estatística Q igual 27,17847, a um nível de significância de 5%, o valor tabelado do Qui-quadrado, para 22 graus de liberdade é de 33,92446, o que confirma a hipótese nula que os resíduos são brancos.
Após a avaliação da FAC e PACF das séries de resíduos dos dois modelos, pode-se perceber que as séries dos resíduos dos dois modelos apresentam comportamento de uma série de resíduos brancos, ou seja, as séries podem ser consideradas aleatórias. As análises das estatísticas dos dois modelos indicaram que o modelo 2 possui um Erro percentual médio absoluto (MAPE) inferior ao do modelo 8, mas em contrapartida o modelo 8 apresenta um R² superior ao do modelo 2 e por este motivo foi escolhido como o modelo de previsão da variável consumo de aço.
Para realizar as previsões do consumo de aço através do modelo SARIMA (0, 1, 1)(1, 0, 0)12 optou-se por 11 períodos adiante do período utilizado para identificação do modelo, ou seja, as previsões são relativas ao período de junho de 2012 a abril 2013, apresentadas na Tabela 3. Este conjunto de previsões apresentou um MAPE de 15,26%.
Tabela 3 – Previsões mensais do consumo de aço – jun./12 – abr./13
|
|
|
|
|
|
2012:06 |
1769409,3 |
1041842,7 |
2496976 |
1988447,0 |
11,0% |
2012:07 |
1926607,4 |
1154947,1 |
2698268 |
2184883,0 |
11,8% |
2012:08 |
2030349,9 |
1216982,7 |
2843717 |
2968178,0 |
31,6% |
2012:09 |
1932339,8 |
1079302,4 |
2785377 |
1818111,0 |
-6,3% |
2012:10 |
2005348,3 |
1114405,3 |
2896291 |
2239756,0 |
10,5% |
2012:11 |
1869176,4 |
941875,93 |
2796477 |
2188962,0 |
14,6% |
2012:12 |
1967756,3 |
1005471,2 |
2930041 |
1581586,0 |
-24,4% |
2013:01 |
1691946 |
695904,14 |
2687988 |
1914027,0 |
11,6% |
2013:02 |
1882627,7 |
853936,35 |
2911319 |
1819222,0 |
-3,5% |
2013:03 |
2112353,2 |
1052017,1 |
3172689 |
1697094,0 |
-24,5% |
2013:04 |
1839057,2 |
747993,93 |
2930121 |
2244515,0 |
18,1% |
Fonte: Elaborado pelo pesquisador
Esta etapa da pesquisa consistiu na construção de um modelo para previsão de consumo de aço através de metodologia de Função de Transferência de Box e Jenkins. Para a construção do modelo foi utilizado o pacote estatístico Autobox (versão 1.2), este gerou de forma automática os modelos com base nas variáveis informadas. O software Autobox apresenta uma limitação quanto ao número de variáveis independentes, este só trabalhava com 5 variáveis independentes por vez, por este motivo foi necessário rodar mais que um modelo. Com base nas variáveis informadas, o software identificou quatro para o modelo de função de transferência, sendo elas: Índice de Indicadores da produção - Extrativa mineral; Produção de Retroescavadeiras; Índice de Indicadores da produção - Indústria de transformação; Índice de Material de construção.
Após identificar as variáveis o software iniciou o processo de pré-branqueamento das variáveis, que consistiu em identificar modelos univariados para cada uma das variáveis selecionadas para fazerem parte do modelo com função de transferência. A tabela 4 traz um resumo dos resultados obtidos na análise de resíduos de cada um dos modelos e das previsões dos modelos.
Tabela 4 – Resumo das Análises de Resíduos e das previsões mensais dos
modelos univariados identificados - dezembro de 2012 a maio de 2013
Variável |
Modelo |
Q |
Qui-quadrado |
MAPE |
Índice de Indicadores da produção Extrativa mineral |
ARIMA(1, 1, 0) |
17,76516 |
33,92446 |
6,62% |
Produção de Retroescavadeiras |
ARIMA(1, 1, 0) |
22,96401 |
33,92446 |
17,01% |
Índice Indicadores da Produção da Indústria de Transformação |
ARIMA(1, 1, 1) |
26,22624 |
32,67056 |
3,63 % |
Índice de Material de Construção |
SARIMA (2, 0, 1)(1, 0, 0)12 |
25,70741 |
31,41042 |
4,94 % |
Fonte: Elaborado pelo pesquisador
A análise do teste de Portmanteau, de todos os modelos identificados, para o conjunto de autocorrelações a um nível de significância de 5% confirmou a hipótese nula de que os resíduos são brancos para todos os modelos.
Após o processo de pré-branqueamento das séries o software realizou o processo de identificação do modelo de função de transferência. A Tabela 5 apresenta os resultados obtidos.
Tabela 5 – Identifica cão do Modelo de Função de Transferência
Variável Dependente: (Y) - Consumo de Aço Número de Observações: 65 Diferenciação: Não |
|||
Série do Ruído Diferenciação sobre o ruído: Nenhum |
|||
Parâmetros do modelo de Ruído |
|||
Elemento |
Lag |
Coeficiente |
Estatística t |
1 – Média |
|
0,15851E+01 |
41,13 |
Primeira Série de Entrada |
|||
Variável Independente: (X1) - Índice de Indicadores da Produção Extrativa Mineral Número de Observações: 65 Diferenciação: Sim, uma de primeira ordem Valor do parâmetro de atraso: 5 |
|||
Parâmetros do modelo de Função de Transferência |
|||
Elemento |
Lag |
Coeficiente |
Estatística t |
2 – Lag de Entrada |
1 |
-0,56866E+00 |
-2,27 |
3 – Lag de Saída |
0 |
0,11654E+01 |
2,35 |
(conclusão) |
|||
Segunda Série de Entrada |
|||
Variável Independente: (X2) Produção de Retroescavadeiras Número de Observações: 65 Diferenciação: Não – (Média presumida da série 0,43642E+01) Valor do parâmetro de atraso: 0 |
|||
Parâmetros do modelo de Função de Transferência |
|||
Elemento |
Lag |
Coeficiente |
Estatística t |
4 – Lag de Entrada |
0 |
0,18580E+00 |
6,29 |
Terceira Série de Entrada |
|||
Variável Independente: (X3) - Índice Indicadores da Produção da Indústria de Transformação Número de Observações: 65 Diferenciação: Sim, uma de primeira ordem Valor do parâmetro de atraso: 4 |
|||
Parâmetros do modelo de Função de Transferência |
|||
Elemento |
Lag |
Coeficiente |
Estatística t |
5 – Lag de Entrada |
0 |
0,21039E+01 |
2,65 |
6 – Lag de Entrada |
12 |
0,13305E+01 |
1,84 |
Quarta Série de Entrada |
|||
Variável Independente: (X4) – Índice de Material de Construção Número de Observações: 65 Diferenciação: Não - (Média presumida da série 0,88120E+00) Valor do parâmetro de atraso: 6 |
|||
Parâmetros do modelo de Função de Transferência |
|||
Elemento |
Lag |
Coeficiente |
Estatística t |
7 – Lag de Entrada |
0 |
0,13980E+01 |
2,24 |
8 – Lag de Entrada |
1 |
0,19229E+01 |
2,79 |
Fonte: Elaborado pelo pesquisador
As Tabela 6 e 7 apresentam, respectivamente, as estatísticas do modelo e as estatísticas da análise de correlação dos resíduos do modelo de função de transferência para consumo de aço.
Tabela 6 – Estatísticas do Modelo de Função de Transferência para variável Consumo de Aço
SOMA DOS QUADRADOS: 0,27036E+01 |
GRAUS DE LIBERDADE: 40 |
MEAN SQUARE : 0,67591E-01 |
NÚMERO DE RESÍDUOS : 48 |
R²: 0,66670E+00 |
CRITÉRIO DE AKAIKE (AIC): -0,25433E+01 |
CRITÉRIO DE BAYES (BIC):-0,22314E+01 |
|
Fonte: Elaborado pelo pesquisador
Tabela 7 – Estatísticas da análise de correlação dos resíduos
Modelo de Função de Transferência
MÉDIA DA SÉRIE DE RESÍDUOS: -0,25183E-05 |
DESVIO PADRÃO: 0,23733E+00 Nº DE OBSERVAÇÕES: 48 |
MÉDIA DIVIDIDA PELO ERRO PADRÃO: -0,73515E-04 |
Fonte: Elaborado pelo pesquisador
Avaliando as estatísticas apresentadas foi possível verificar que o modelo apresenta valores para AIC e BIC baixos, o que indica um modelo parcimonioso. Além disso também é possível verificar que o coeficiente de determinação (R²) tem um valor de 0,6759, o que significa que 67,59% da variável consumo de aço pode ser explicada pelo elementos deste modelo.
A verificação do modelo identificado foi realizada através da análise dos gráficos da FAC dos resíduos da função de transferência e análise das correlações cruzadas entre os resíduos do modelo e os resíduos de cada uma das variáveis independentes.
A análise do FAC dos resíduos da função de transferência para variável consumo de aço indica que todos os lags encontram-se dentro dos limites de confiança com p valores significativos. Para confirmar esta primeira interpretação foi realizado o teste de Portmanteau, que apresentou uma estatística Q igual 17,85808, a um nível de significância de 5% o valor tabelado do Qui-quadrado, para 16 graus de liberdade foi 26,29622, o que confirma a hipótese nula de que os resíduos são brancos.
Na avaliação das correlações cruzadas foi utilizada a estatística S, com um nível de significância de 5%. Os resultados obtidos foram comparados com o valor tabelado da distribuição qui-quadrado. Todos os resultados mostraram-se significativos indicando que as correlações cruzadas entre os resíduos do pré-branqueamento e os resíduos da função de transferência são ruídos brancos. Além disso, os resultados obtidos confirmam a casualidade unidirecional entre os resíduos.
Como última etapa de avaliação do modelo, foi calculado o MAPE das previsões relativo ao período de janeiro de 2007 a maio de 2012 que apresentou o valor de 9,95%, o que representa uma boa capacidade de descrever o comportamento da série no passado.
Após a realização da etapa de validação do modelo de função de transferência para o consumo de aço, este mostrou-se adequado para a realização de previsões.
Após a identificação dos modelos univariado e de função de transferência, para a variável consumo de aço, foi possível verificar que os dois modelos apresentam resultados significativos tanto na capacidade de descrever a série quanto na capacidade de previsão.
Com relação à capacidade dos modelos descreverem a série de consumo de aço no período de janeiro de 2007 a maio de 2012, o modelo univariado SARIMA (0, 1, 1)(1, 0, 0)12 apresentou um R² igual a 75,32% e MAPE de 24,19% e o modelo de função de transferência apresentou um MAPE igual a 9,95% e R² de 67,59%, ou seja, o modelo de função de transferência apresenta um menor erro e um coeficiente de determinação inferior, o que indica que o modelo univariado, mesmo tendo um MAPE superior, tem uma capacidade de explicar o comportamento da série melhor que o modelo de função de transferência.
Quanto à avaliação da capacidade dos dois modelos preverem o futuro, o modelo univariado SARIMA (0, 1, 1)(1, 0, 0)12 apresentou um MAPE de 15,26% e o modelo de função de transferência apresentou o MAPE de 17,28%, ou seja, o modelo univariado obteve melhores resultados de previsão.
No contexto de um processo de inteligência competitiva acredito que os dois modelos podem assumir funções muito importantes. O modelo univariado pode ser uma ferramenta para avaliar as séries históricas do consumo de aço, ou seja, através dele a empresa pode estudar os seus dados históricos e encontrar informações que podem ser transformadas em conhecimento fundamental dentro do processo decisório.
O modelo de função de transferência combinado como um monitoramento do mercado, para identificação das variáveis externas, pode assumir um papel equivalente ao do univariado, mas com base na combinação de informações internas e externas da empresa para a empresa prever o possível consumo de aço.
A combinação dos resultados obtidos pelos dois modelos será capaz de trazer mais dados e informações para os gestores da empresa e subsidiar as decisões referentes ao planejamento de compra de Aço.
O objetivo geral desta pesquisa foi identificar modelos de previsão de consumo de aço para análise das informações no processo de Inteligência Competitiva (IC) em uma empresa do setor metalúrgico combinando fenômeno Big Data, Data Mining e modelos de previsão como um modelo teórico para o processo de Inteligência Competitiva.
A pesquisa mostrou que fenômeno do Big Data (BD) é realmente uma fonte importante de dados, mas que devido a suas características de dimensão, diversidade de dados, estrutura dos dados, velocidade de crescimento dos dados e principalmente a limitação para armazenamento destes, exige que as empresas ou instituições governamentais mantenham uma estrutura física e humana muito bem preparada para o monitoramento dos dados existentes. Essa estrutura passa pelo desenvolvimento do processo de Inteligência Competitiva dentro das empresas, pois através da IC a empresa poderá manter o foco nas informações externas característica que para Trapanof (2001, p. 45) torna a IC um conjunto de ferramentas útil para a gestão da informação. É importante destacar que não basta reconhecer o BD como uma fonte de informações. A empresa deve saber explorar esta fonte através de um processo de IC, o que vai exigir que ela possua pessoal com qualificação para realizar este processo.
Tendo o Big Data como uma fonte de informações a pesquisa também demostrou a importância do Data Mining (DM) como ferramenta de análise de grande volume de informação do BD. Mesmo que realizado de forma artesanal, o DM se apresentou como uma ferramenta muito importante no desenvolvimento do trabalho, pois através dele foi possível identificar as variáveis internas e externas para posterior identificação do modelo de previsão.
Por fim, a pesquisa tinha como objetivo construir modelos de previsão de consumo de aço através da análise de Séries Temporais. Este objetivo foi realizado de forma mais ampla, pois não se construiu um modelo e sim dois modelos. O primeiro modelo construído foi um modelo univariado sem intervenção. O objetivo da construção deste modelo foi o de permitir que a empresa monitore a sua demanda de aço com base nos dados históricos da própria empresa, ou seja, o uso das informações internas em um processo de IC. O modelo identificado apresentou bons resultados tanto na sua capacidade de descrever o passado da série de consumo de aço quanto na capacidade de previsão. O segundo modelo consistiu em um modelo de previsão com Função de Transferência. A construção deste teve como objetivo a combinação das informações internas da empresa com variáveis econômicas externas que tivessem relação com os clientes da empresa, e correlação com o consumo de aço. Este modelo apresentou melhores resultados na capacidade de descrever o comportamento passado da série de consumo de aço da empresa comparado com o modelo univariado, porém um resultado um pouco inferior na capacidade de previsão. A utilização dos modelos encontrados pode ser uma ferramenta muito importante em um processo de IC, pois possibilitarão uma previsão de consumo de aço através de um monitoramento conjunto das séries históricas da empresa e de informações provenientes do mercado externo. Na realização deste último objetivo ficou caracterizada a Inteligência Competitiva, pois para atingi-lo foi necessário um processo dinâmico de combinação de diversas áreas do conhecimento para coletar, organizar e disseminar o conhecimento nas informações obtidas na empresa e no mercado com o intuito de auxiliar a tomada decisões.
Por fim, o estudo atingiu o objetivo geral ao combinar os resultados obtidos em cada um dos objetivos específicos. Ao atingir este objetivo foi possível confirmar um modelo teórico, onde fenômeno Big Data, Data Mining e modelos de previsão mostram-se como instrumentos de análise em um processo de Inteligência Competitiva. A relevância deste estudo está exatamente no fato de que a utilização do modelo teórico possibilitará tanto para a área acadêmica quanto para os profissionais de áreas afins um novo instrumento de Inteligência Competitiva.
BACEN, Banco Central do Brasil. SGS - Sistema Gerenciador de Séries Temporais. Disponível em:<https://www3.bcb.gov.br/sgspub/localizarseries/localizarSeries.do
?method=prepararTelaLocalizarSeries>. Acesso em: 10 jun. 2012.
BOX, G. E. P.; JENKINS, G. M.; REINSEL, G. C. Time series analysis: forecasting and control. 4. ed. Hoboken, N.J.: Wiley, 2008. xxiv, 746 p.
BOX, George E. P.; JENKINS, Gwilym M.; REINSEL, Gregory C. Time series analysis: forecasting and control. 4.ed. Hoboken, N.J.: Wiley, 2008. xxiv, 746 p.
BRAGA, L. P. V.. Introdução à mineração de dados. 2. ed. ampl. e rev. Rio de Janeiro: E-Papers, 2005. 211 p.
BRASIL. Ministério da Fazenda. - (Org.). Emissão de Comprovante de Inscrição e de Situação Cadastral: Receita Federal. Disponível em: <http://www.receita.fazenda.gov.br/PessoaJuridica/CNPJ/cnpjreva/Cnpjreva_Solicitacao.asp>. Acesso em: 20 maio 2012.
CAMARGO, M. E.; SOUZA, R. C.. Análise e previsão de Séries Temporais: Os Modelos ARIMA. Ijuí: Sedigraf, 1996. 242 p.
CRESWELL, J. Projeto de pesquisa: métodos qualitativo, quantitativo e misto. 2. ed. Porto Alegre: Bookman, 2007.
DAVENPORT, T. H. Ecologia da informação: por que só a tecnologia não basta para o sucesso na era da informação. São Paulo: Futura, [1998]. 316 p.
DAVENPORT, T. H.; HARRIS, J. G. Competição analítica: vencendo através da nova ciência. Rio de Janeiro: Elsevier, c2007. 241 p.
DRUCKER, P. F.. Sociedade pós-capitalista. São Paulo, SP: Thomson, c1993. 186 p.
EMC - Big Data: Big Opportunities to Create Business Value. EMC Corporation, Hopkinton, Massachusetts, nov. 2011. Disponível em: <http://www.emc.com/microsites/cio/articles/big-data-big-opportunities/LCIA-BigData-Opportunities-Value.pdf>. Acesso em 03 ago 2012.
ESPÍNDOLA, A. M. S.; ROTH, L.; CAMARGO, M.E.; FACHINELLI , A.C..Big Data and Strategic Intelligence: A Case Study on Data Mining as an Alternative Analysis. Espacios. Vol. 37 (Nº 04) Año 2016. Pág. 16
FACHINELLI,A.C.; MATTIA,O.M.; RECH,J..; ROVEDA, V.. Vigília e inteligência estratégica: ferramentas metodológicas para a definição de estratégias de relações públicas. Conexão - Comunicação e Cultura, Vol. 6, Nº 11 (2007). Acesso em: 15 out. 2012.
FISCHER, S. L.; Séries univariantes de tempo - metodologia de Box & Jenkins. Porto Alegre: Fundação de Economia e Estatística, 1982. 186p. (Teses 4)
FLEISHER, C. S., WRIGHT, S., ALLARD H. T. The role of insight teams in integrating diverse marketing information management techniques, European Journal of Marketing, Vol. 42 Iss: 7 pp. 836 – 851. Disponível em: <http://dx.doi.org/10.1108/03090560810877187>. Acesso em: 25 nov. 2012.
GIL, A. C. Como elaborar projetos de pesquisa. 4. ed. São Paulo: Atlas, 2002.
GUJARATI, D. N.. Basic econometrics. 3.ed. New York, US: McGraw-Hill, 1995. 838 p.
HAIR JR., J. F. Jr.; ANDERSON, R. E.; TATHAM, R. L.; BLACK, W. C. Análise Multivariada de Dados. 5. ed. Porto Alegre: Bookmann, 2005.
IABR, Instituto De Aço Brasil. Dados do Mercado. Disponível em: <http://www.acobrasil.org.br/site/portugues/numeros/numeros--mercado.asp>. Acesso em: 01 jun. 2012.
IBGE, Instituto Brasileiro de Geografia e Estatística. Comissão Nacional de Classificação: Tabela CNAE. Disponível em: <http://www.cnae.ibge.gov.br/>. Acesso em: 04 jun. 2012.
IDC - International Data Corporation. THE 2011 Digital Universe Study: Estracting Value from Chaos – Big Value from Big Data. Disponível em: <http://brazil.emc.com/collateral/demos/microsites/emc-digital-universe-2011/index.htm>.Acesso em 05 ago. 2012.
MALHOTRA, N. K. Pesquisa de marketing: foco na decisão. 3. ed. São Paulo: Pearson, 2010. XX, 491 p.
MCKINSEY, Global Institute. Big Data: The next frontier for innovation, competition, and productivity, 2011.
MME, Ministério de Minas e Energia. Anuário Estatístico do Setor Metalúrgico 2011 - ano base 2010. Disponível em: <http://www.mme.gov.br/sgm/menu/publicacoes.html>. Acesso em: 20 jun. 2012.
MORETTIN, P. A.; TOLOI, C. M. C.. Modelos para Previsão de Séries Temporais. In : 13° Colóquio Brasileiro de Matemática. Rio de Janeiro : [s.n.], 1981.
MORETTIN, P. A.; TOLOI, C. M.. Análise de séries temporais. 2. ed. São Paulo: Edgard Blucher, 2006. 538 p.
MORETTIN, P. A.; TOLOI, C. M.. Séries temporais. 2. ed. São Paulo: Atual, 1987. 136 p.
NONAKA, I.; TAKEUCHI, H.. Criação de conhecimento na empresa: como as empresas japonesas geram a dinâmica da inovação. 10. ed. Rio de Janeiro: Campus, 2002. 358 p.
PEREIRA, R., S. A Estatística e Suas Aplicações. Porto Alegre: Edição do Autor, 1979.
SAMPIERI, R. H.; COLLADO, C. F.; LUCIO, P. B.. Metodología de la investigacion. 2. ed. México: Mckraw-hill, 2001. 501 p.
SANTOS, C. Estatística Descritiva - Manual de Auto-aprendizagem, Lisboa, Edições Silabo, 2007.
SOUZA, R. C.. Modelos Estruturais para Previsão de Séries Temporais: Abordagens Clássica e Bayesiana. In : 17° Colóquio Brasileiro de Matemática. Rio de Janeiro, 1989.
STEWART, T. A.. Capital intelectual: a nova vantagem competitiva das empresas. 7. ed. Rio de Janeiro: Campus, 1998.
TARAPANOFF, K.. Inteligência organizacional e competitiva. Brasília: UnB, 2001.
YIN, R. K. Estudo de caso: planejamento e métodos. 4. ed. Porto Alegre: Bookman, 2010. XVIII, 248 p.
1. Email: mariaemiliappga@gmail.com