1. Introdução
A acuracidade da informação é um atributo fundamental nos processos de tomada de decisão no ambiente organizacional, sob pena de comprometer o resultado das metas previamente estabelecidas. Nesse sentido, a melhoria contínua dos indicadores de qualidade em sistemas produtivos também depende da assertividade da coleta e registro de dados das não conformidades encontradas. Assim como, do direcionamento das análises dos dados. A visão tradicional do Gerenciamento da Qualidade Total (Total Quality Management-TQM) propõe a redução sistemática das não-conformidades na fábrica. Contudo, as tradicionais sete ferramentas da qualidade, amplamente difundidas nas indústrias de manufatura, tais como como: o gráfico de Pareto, o diagrama de Ishikawa e o DOE (Design of Experiments) possuem como pressuposto a análise individual ou análise linear entre fatores. Ou seja, enquanto o gráfico de Pareto, por exemplo, quantifica o número de ocorrências de determinados defeitos individualmente, o diagrama de Ishikawa estrutura a relação de causa-efeito e o DOE mede o impacto do(s) fator(es) A no(s) fator(es) B.
Todavia, a fim de dar maior robustez na análise das não conformidades de qualidade no contexto industrial, essa pesquisa irá discutir uma abordagem que gera relações hierarquizadas, quantitativas e cruzadas no banco de dados de registros dos defeitos de qualidade. Nesse sentido, essa pesquisa se propõe a investigar a aplicação da mineração de dados em sistemas de qualidade no ambiente industrial. Para explicitar a questão de pesquisa desse estudo usaram-se os dados de um estudo de caso prático de uma empresa brasileira. Escolheu-se um processo crítico de produção que impacta diretamente na qualidade final dos seus produtos. Tal processo é a fabricação de trocadores de calor e a característica em análise é o vazamento que ocorrem nos trocadores de calor.
De forma a organizar a discussão proposta nesse artigo, a condução da pesquisa se deu da seguinte maneira: a seção dois apresenta objetivamente o referencial teórico sobre gestão da qualidade e a mineração de dados; a seção três apresenta o ambiente de aplicação do estudo de caso e descreve a metodologia de pesquisa adotada; já a seção quatro efetivamente sistematiza a aplicação do estudo de caso ao realizar as associações necessárias usando a mineração de dados; na seção cinco são tecidas as discussões e implicações da pesquisa e por a seção seis finaliza a pesquisa com as principais conclusões e implicações de trabalhos futuros.
2. Referencial teórico
2.1 Total Quality Management (TQM)
Segundo Feigenbaum (1991) o TQM é uma filosofia e um conjunto de princípios que objetivam a melhoria contínua de processos, baseado na aplicação de análises quantitativas, qualitativas e no envolvimento das pessoas para alavancar melhorias nos processos e atender às necessidades dos clientes. A Figura 1 apresenta uma síntese da evolução histórica dos métodos de qualidade até a consolidação do que denominamos TQM. O TQM é uma filosofia para alcançar excelência no desempenho dos negócios através do uso e aplicação de técnicas e ferramentas específicas, como o envolvimento das pessoas, as sete ferramentas da qualidade de desenvolvidas por Ishikawa (JURAN & GRYNA, 1980).
Figura 1 – Evolução histórica dos métodos de qualidade. Fonte: Feigenbaum (1991).
Deming (1986) contribuiu significativamente para a construção do atual modelo de TQM ao desenvolver os 14 princípios de gerenciamento da qualidade. Deming defende que todos os tomadores de decisão nas empresas precisam ter um profundo conhecimento sobre o sistema sobre o qual a organização opera e para tanto elaborou uma metodologia chamada System of Profound Knowledge (SPK) eaplicou em inúmeras empresas. Para Berry (1991) o objetivo do TQM deve ser exceder as expectativas dos clientes e buscar a redução de custos internos melhorando continuamente os processos e qualidade, a partir da adoção de uma nova cultura organizacional. Os fatores críticos de sucesso na implantação do TQM envolvem aspectos culturais e gerenciais e há diversas pesquisas na literatura sobre tais aspectos.
2.2 Descoberta de conhecimento em banco de dados (Knowledge Discovery in Database -KDD)
Para Fayyad et al. (1996), KDD é o processo que envolve a automação da identificação e do reconhecimento de padrões em um banco de dados. A KDD é a extração da informação interessante ou padrões dos dados em bases de dados e para os autores suas etapas são expressas conforme a Figura 2.
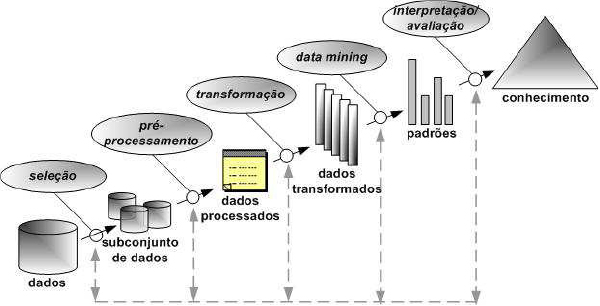
Figura 2 – Fases do processo de KDD. Fonte: Fayyad et al. (1996).
A seguir serão detalhadas as etapas do KDD segundo Han e Kamber (2000):
Seleção de Dados: são escolhidos apenas os atributos relevantes do conjunto de atributos da base de dados. Ou seja, faz-se a seleção de um subconjunto de atributos relevantes para o objetivo da tarefa. O subconjunto selecionado é então fornecido para a mineração de dados.
Pré-processamento dos dados: o objetivo é assegurar a qualidade dos dados selecionados. A limpeza dos dados envolve a verificação da consistência das informações, a correção de possíveis erros e o preenchimento ou a eliminação de valores nulos e redundantes. São identificados e removidos os dados, duplicados e os ruídos. A execução dessa fase corrige a base de dados eliminando consultas desnecessárias que seriam executadas pelo algoritmo minerador e que afetariam o seu processamento.
Transformação de Dados: o objetivo da transformação de dados é converter o conjunto bruto de dados em uma forma padrão de uso. Os dados do atributo podem ser padronizados dentro de uma faixa de valores, como por exemplo: 0 a 1. A Transformação de Dados é potencialmente a tarefa que requer grande habilidade no processo de KDD. Tipicamente essa etapa exige a experiência do analista de dados e seu conhecimento nos dados em questão.
Data Mining (Mineração de Dados): Segundo Adriaans e Zantinge (1996), existe uma confusão entre os termos Data Mining e KDD. O termo KDD é empregado para descrever o processo de extração de conhecimento de um conjunto de dados. Assim, conhecimento significa relações e padrões entre os elementos dos conjuntos de dados. Enquanto que o termo Data Mining deve ser usado exclusivamente para o estágio de descoberta de conhecimento do processo de KDD. Uma definição detalhada será apresentada no capítulo 2.3.
Interpretação e Avaliação do Conhecimento: após a mineração de dados é necessária a interpretação do conhecimento descoberto, ou algum processamento desse conhecimento. O objetivo dessa fase é melhorar a compreensão do conhecimento descoberto pelo algoritmo minerador, validando-o através de medidas da qualidade da solução e da percepção de um analista de dados. Já para Adriaans e Zantinge (1996) são sete as fases de um processo de KDD: definição do problema, seleção dos dados, eliminação de incongruências e erros dos dados (filtragem dos dados), enriquecimento dos dados, codificação dos dados, data mining e relatórios de análise.
2.3 Mineração de Dados (Data Mining-MD)
Data Mining ou mineração de dados é uma área de pesquisa multidisciplinar, incluindo principalmente as tecnologias de bancos de dados, inteligência artificial, estatística, reconhecimento de padrões, sistemas baseados em conhecimento, recuperação da informação, computação de alto desempenho e visualização de dados. A análise de dados tradicional é baseada na suposição, em que uma hipótese é formulada e validada por meio de dados. Por outro lado, as técnicas de data mining são baseadas na descoberta, na medida em que os padrões são automaticamente extraídos do conjunto de dados (CARDOSO & MACHADO, 2008). Fayyad et al. (1996), definiram a mineração de dados como um processo não trivial de identificar, em dados, padrões válidos, novos, potencialmente úteis e ultimamente compreensíveis.
Para realizar a KDD, alguns indicadores de análise devem ser considerados no estudo de KDD. Os indicadores mais utilizados nas análises dos bancos de dados são:
a) Suporte: O suporte de uma determinada regra mede a frequência com que esse padrão aparece na base de dados.
b) Confiança: corresponde a um valor de correlação entre os itens que formam esse padrão. Para evitar que se gere um número de regras quase tão elevado quanto o número de transações em análise, geralmente condicionam-se as regras para um suporte baixo e uma confiança elevada.
c) Conviction: a medida conviction permite medir a independência do antecedente A, face ao conseqüente B (BRIN et al., 1997b). Trata-se de uma medida unidirecional, isto é, a conviction(A=>B) é diferente da conviction(B=>A). O valor de conviction pode variar entre 0 e +∞, apresentando o valor 1 quando os conjuntos A e B são independentes. Assim, esta medida pode representar-se do seguinte modo:
conviction (A=> B)= P(A∩B)/(P(A) * P(B) )
d) Leverage: a medida leverege define a diferença entre a proporção de exemplos cobertos, simultaneamente, pelo antecedente e pelo consequente da regra e a proporção de exemplos que seriam cobertos se o antecedente e o consequente fossem independentes. Assim, esta medida pode representar-se do seguinte modo:
leverage (A=> B)= suporte (A∩B) – (suporte(A) * suporte(B))
e) Interest ou Lift: o Interest ou Lift de uma regra A=>B corresponde ao quociente entre a probabilidade conjunta (de A e B) observada e a probabilidade conjunta sob independência (BRIN et al., 1997b). Esta medida pode ser representada da seguinte forma:
interest (A=> B) = suporte(A , B)/suporte(A)*suporte(B)
3. Metodologia de pesquisa
Para realizar o estudo de caso usou-se a base de dados de registros das não-conformidades do sistema de gerenciamento da qualidade de uma empresa do segmento metal-mecânico, situada do Rio Grande do Sul. Escolheu-se o produto (trocador de calor) do portfólio da empresa que possui histórico de consideráveis rejeições de qualidade a partir da sugestão apontada pela gerência da empresa. A base dados de trabalho possui registros das não-conformidades ocorridas durante o ano de 2009. Para o desenvolvimento do trabalho primeiro aplicou-se a técnica de mineração de dados e em seguida a análise dos resultados e a discussão de aspectos que permitem ou não propor um modelo integrado entre TQM e DM. Para aplicar a MD usou-se o software WEKA (Waikato Environment for Knowledge Analysis) desenvolvido na Universidade de Waikato de Hamilton, Nova Zelândia. O WEKA é um pacote computacional de KDD, que possui código-aberto formado por um conjunto de implementações de algoritmos de diversas técnicas de MD. O WEKA é comumente usado em pesquisas na área de aprendizagem de máquina, porque apresenta componentes que facilitam o uso de algoritmos classificadores. Dentre esses algoritmos podemos citar o Apriori e o J48. Essa pesquisa usará o algoritmo Apriori para a análise das associações no banco de dados. Para que os dados fossem manipulados nos algoritmos de mineração de dados através da ferramenta WEKA, realizou-se a adaptação do banco de dados transformando-os no formato padrão da ferramenta, denominado ARFF (Atribute Relation File Format). O arquivo ARFF foi criado a partir de um banco de dados de planilhas eletrônicas de registros de não-conformidades da empresa, o qual foi transformado posteriormente para a extensão padrão da ferramenta (ARFF).
4. Análise e discussão do estudo de caso
Para aplicar o estudo de caso escolheram-se na base de dados de indicadores de qualidade da empresa as operações do sistema produtivo que mais apresentavam defeitos relacionados a vazamentos no produto trocador de calor. As variáveis de análise da base de dados são: o mês de produção, o tipo de produto onde é usado o trocador de calor, o fornecedor do componente que gerou a falha, a operação da linha de montagem onde se identificou o defeito e os tipos de defeitos possíveis de ocorrer. As variáveis analisadas estão apresentadas na Tabela 2.
Tabela 2 – Variáveis analisadas
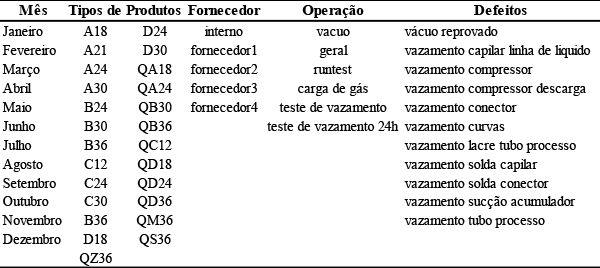
Fonte: autores (2013).
Os dados foram gerados no formato exigido pelo WEKA e usou-se o algoritmo Apriori para gerar as regras de associação. O resultado da exploração inicial da base de dados e os indicadores de análise estão apresentados na Tabela 3.
Tabela 3 – Resultado exploração inicial da base de dados

Fonte: autores (2013).
A partir da análise das 20 regras de associação geradas verificou-se que as associações estavam relacionadas ao produto B30, à operação vácuo e ao defeito de vácuo reprovado. A partir dos valores dos indicadores de Tabela 3, verificou-se um forte relação entre a reprovação de vácuo e o produto B30. O não aparecimento das outras variáveis sugerem a importância e o considerável impacto dessas variáveis no controle de qualidade da empresa. A exploração inicial não mostrou regras para os demais defeitos, operações e tipos de produtos. Provavelmente esse fato deve-se à quantidade de ocorrências das variáveis supracitadas na base de dados e para ponderar esse aspecto uma nova análise foi rodada, excluindo da base de dados as ocorrências correlacionadas com tais variáveis, a fim de analisar outras regras de associação. O resultado dessa segunda análise esta apresentado na Tabela 4.
Tabela 4 – Resultado da segunda exploração da base de dados

Fonte: autores (2013).
Dadas as vinte regras geradas, treze foram selecionadas como representativas a partir dos indicadores. Verificou-se que a retirada da base de dados da variável operação de vácuo possibilitou a criação de novas regras de interesse e conhecimento a partir da base de dados.
5. Discussão dos resultados
Inicialmente será analisado o resultado da mineração de dados resultantes da Tabela 3. Analisando a regra 1 gerada, verifica-se que o produto B30 teve 203 ocorrências na operação vácuo pelo mesmo defeito de vácuo reprovado, sem haver regra quanto ao mês de incidência. É possível pontuar que tal produto precisa ser reavaliado pelo grupo de especialistas da empresa para identificar a causa do problema, já que a operação já foi identificada. A análise das regras 2 e 3 mostra que todos os defeitos na operação vácuo apontaram para um único defeito de vácuo reprovado. Um questionamento que pode ser feito nesse ponto é se existem outros defeitos que podem ocorrer nessa operação e que poderiam ser adicionados na base de cadastro da empresa. A análise da regra 4 reforça o conhecimento gerado na regra 1 e mostra que as principais ocorrências de qualidade ocorrem em itens fabricados na própria empresa e não em itens fornecidos. A regra 5 mostra que o principal defeito de qualidade registrados internamente é o vácuo reprovado, e essa informação pode ajudar a empresa a focar esforços de melhorias.
As regras de associação geradas na Tabela 4 mostram o conhecimento extraído das demais variáveis, já que foram retiradas as ocorrências de vácuo reprovado por ser a de maior frequência. Das 20 regras geradas, foram selecionas as 13 com melhores indicadores de confiança e conviction. A análise da regra 1 mostra que a operação com maior incidência (55%) de falhas em novembro foi a carga. Provavelmente alguma causa especial ocorreu nesse período. Analisando a regra 2 verifica-se que todas as incidências de vazamento nas curvas são geradas pelos processo da fábrica e não por itens fornecidos.
As regras 3, 10 e 13 mostram que o fornecedor 3 contribui significativamente com o desempenho de qualidade do sistema produtivo e que ações junto com o fornecedor para identificar a solução devem ser conduzidas. O conhecimento gerado pelas regras 4, 5, 8 e 9 permite verificar que o mês de agosto foi o que mais gerou defeitos de vazamento e que tubo de processo, um item fornecido por uma empresa local, foi a principal causa.
A análise da regra 6 traz um tipo de defeito que não tinha aparecido nas outras regras. Dentre as 162 ocorrências no período na operação vazamento, 42(26%) foram causadas por vazamento na sucção do acumulador. As regras 7, 11 e 12 mostram que o produto B30, é o que apresenta mais ocorrências de vazamento reforçando os resultados obtidos na tabela 3.
6. Conclusão
Esse artigo buscou evidenciar se o conhecimento gerado a partir da mineração de dados usando o algoritmo Apriori pode ser aplicado nos processos de gerenciamento da qualidade de empresas industriais. O primeiro objetivo do artigo de aplicar a técnica de mineração de dados para identificar associações não explicitadas pelo TQM foi atendido. Isso porque as regras de associações geradas, permitiram a análise e identificação de regras de interesse na Tabela 3 e sobretudo na Tabela 4. Outra contribuição dessa pesquisa se refere ao potencial de análise oferecido pelos indicadores da mineração de dados, sobretudo pelos indicadores Lift e a Confiança. O uso combinado do resultado das regras de associação, com seus indicadores e as ferramentas da qualidade como o gráfico de pareto, por exemplo, pode ser uma possibilidade a ser investigada em trabalhos futuros.
O segundo objetivo dessa pesquisa foi verificar se a mineração de dados pode ser usada como ferramenta de tomada de decisão nos processos de gerenciamento da qualidade e suas implicações em tal em tal contexto. Nesse contexto, o segundo objetivo foi parcialmente atingido, dado que para efetuar a análise completa de um banco de dados faz-se necessário gerar um elevado número de regras de interesse e a análise dessas regras demandaria longo tempo de trabalho por parte dos analistas de qualidade da empresa. Uma dificuldade percebida no método aqui discutido se refere ao tempo elevado de preparação das bases de dados a partir de planilhas para o formato ARFF com o qual o WEKA trabalha. Assim sendo, trabalhos futuros são sugeridos replicar os objetivos de pesquisa desse estudo usando outros softwares de mineração de dados que possuem um tempo aceitável de preparação da base de dados e análise das regras.
Referências
Adriaans, P.; Zantinge, D. Data mining. Harlow: Addison-Wesley, 1996. 158p.
Andersson, R.; Eriksson, H.; Tortensson, H. (2006), Similarities and differences between TQM, Six Sigma and lean. The TQM Magazine, Vol. 18 No. 3, pp. 282-96.
Bianco, M.; SALERNO, M. Como o TQM opera e o que TQM muda nas empresas? Um estudo de caso a partir de empresas líderes no Brasil. Gestão e Produção. v.8, n.1, p.56-67, abr. 2001
Black, K.; Revere, L. (2006), Six Sigma arises from the ashes of TQM with a twist, International Journal of Health Care Quality Assurance, Vol. 19 Nos 2/3, pp. 259-66
Cardoso, O. ; Machado, R. Gestão do conhecimento usando data mining: estudo de caso na Universidade Federal de Lavras. RAP –Rio de Janeiro 42(3):495-528,maio/jun 2008.
Dahlgaard, J.; Dahlgaard-Park, S. (2006), Lean production, Six Sigma quality, TQM and company culture. The TQM Magazine, Vol. 18 No. 3, pp. 263-81.
Deming, W. E. (1986) Out of the crisis: quality, productivity and competitive position, Cambridge University Press.
Eckes, George. A Revolução Seis Sigma: o método que levou a GE e outras empresas a transformar processos em lucro. 4. ed. Rio de Janeiro: Editora Campos, 2001. 270 p.
Feigenbaum, A. V. (1991) Total quality control, New York, McGraw-Hill.
Ishikawa, K. Controle da qualidade total: à maneira japonesa, tradução Iliana Torres, Rio de Janeiro, 1993, 221p. Business, n.5, abr. 2003.
Juran, J.M.; Gryna, F. M. Controle da qualidade: componentes básicos da função qualidade. São Paulo: McGraw-Hill/Makron, 1991.
Tan, Pang-ning; Steinbach, M.; Kumar, V. Introdução ao data mining - Mineração de Dados. 1. ed. Rio de Janeiro: Ciência Moderna, 2009.